With the recent climb of Bitcoin’s price over 20k $USD, and to it recently breaking 30k, I thought it’s worth taking a deep dive back into creating Ethereum applications. Ethereum, as you should know by now, is a public (meaning, open-to-everyone-without-restrictions) blockchain that functions as a distributed consensus and data processing network, with the data being in the canonical form of “transactions” (txns). However, the current capabilities of Ethereum let it store (constrained by gas fees) and process (constrained by block size or size of the parties participating in consensus) only so many txns and txns/sec. Now, since this is a “how to” article on building with Redwood and Fauna and not an article on “how does […],” I will not go further into the technical details about how Ethereum works, what constraints it has and does not have, et cetera. Instead, I will assume you, as the reader, already have some understanding about Ethereum and how to build on it or with it.
I realized that there will be some new people stumbling onto this post with no prior experience with Ethereum, and it would behoove me to point these viewers in some direction. Thankfully, as of the time of this rewriting, Ethereum recently revamped their Developers page with tons of resources and tutorials. I highly recommend newcomers to go through it!
Although, I will be providing relevant specific details as we go along so that anyone familiar with either building Ethereum apps, Redwood.js apps, or apps that rely on a Fauna, can easily follow the content in this tutorial. With that out of the way, let’s dive in!
Preliminaries
This project is a fork of the Emanator monorepo, a project that is well described by Patrick Gallagher, one of the creators of the app, in his blog post he made for his team’s Superfluid hackathon submission. While Patrick’s app used Heroku for their database, I will be showing how you can use Fauna with this same app!
Since this project is a fork, make sure to have downloaded the MetaMask browser extension before continuing.
Fauna
Fauna is a web-native GraphQL interface, with support for custom business logic and integration with the serverless ecosystem, enabling developers to simplify code and ship faster. The underlying globally-distributed storage and compute fabric is fast, consistent, and reliable, with a modern security infrastructure. Fauna is easy to get started with and offers a 100 percent serverless experience with nothing to manage.
Fauna also provides us with a High Availability solution with each server globally located containing a partition of our database, replicating our data asynchronously with each request with a copy of our database or the transaction made.
Some of the benefits to using Fauna can be summarized as:
- Transactional
- Multi-document
- Geo-distributed
In short, Fauna frees the developer from worrying about single or multi-document solutions. Guarantees consistent data without burdening the developer on how to model their system to avoid consistency issues. To get a good overview of how Fauna does this see this blog post about the FaunaDB distributed transaction protocol.
There are a few other alternatives that one could choose instead of using Fauna such as:
- Firebase
- Cassandra
- MongoDB
But these options don’t give us the ACID guarantees that Fauna does, compromising scaling. ACID stands for:
- Atomic: all transactions are a single unit of truth, either they all pass or none. If we have multiple transactions in the same request then either both are good or neither are, one cannot fail and the other succeed.
- Consistent: A transaction can only bring the database from one valid state to another, that is, any data written to the database must follow the rules set out by the database, this ensures that all transactions are legal.
- Isolation: When a transaction is made or created, concurrent transactions leave the state of the database the same as they would be if each request was made sequentially.
- Durability: Any transaction that is made and committed to the database is persisted in the database, regardless of down time of the system or failure.
Redwood.js
Since I’ve used Fauna several times, I can vouch for Fauna’s database first-hand, and of all the things I enjoy about it, what I love the most is how simple and easy it is to use! Not only that, but Fauna is also great and easy to pair with GraphQL and GraphQL tools like Apollo Client and Apollo Server!! However, we will not be using Apollo Client and Apollo Server directly. We’ll be using Redwood.js instead, a full-stack JavaScript/TypeScript (not production-ready) serverless framework which comes prepackaged with Apollo Client/Server!
You can check out Redwood.js on its site, and the GitHub page.
Redwood.js is a newer framework to come out of the woodwork (lol) and was started by Tom Preston-Werner (one of the founders of GitHub). Even so, do be warned that this is an opinionated web-app framework, coming with a lot of the dev environment decisions already made for you. While some folk may not like this approach, it does offer us a faster way to build Ethereum apps, which is what this post is all about.
Superfluid
One of the challenges of working with Ethereum applications is block confirmations. The corollary to block confirmations is txn confirmations (i.e. data), and confirmations take time, which means time (usually minutes) that the user must wait until a computation they initiated (either directly via a UI or indirectly via another smart contract) is considered truthful or trustworthy. Superfluid is a protocol that aims to address this issue by introducing cashflows or txn streams to enable real-time financial applications; that is; apps where the user no longer needs to wait for txn confirmations and can immediately follow-up on the next set of computational actions.
Learn more about Superfluid by reading their documentation.
Emanator
Patrick’s team did something really cool and applied Superfluid’s streaming functionality to NFTs, allowing for a user to “mint a continuous supply of NFTs”. This stream of NFTs can then be sold via auctions. Another interesting part of the emanator app is that these NFTs are for creators, artists 👩🎨 , or musicians 🎼 .
There are a lot more technical details about how this application works, like the use of a Superfluid Instant Distribution Agreement (IDA), revenue split per auction, auction process, and the smart contract itself; however, since this is a “how-to” and not a “how does […]” tutorial, I’ll leave you with a link to the README.md of the original Emanator `monorepo`, if you want to learn more.
Finally, let’s get to some code!
Setup
1. Download the repo from redwood-eth-with-fauna
Git clone the redwood-eth-with-fauna repo on your terminal, favorite text editor, or IDE. For greater cognitive ease, I’ll be using VSCode for this tutorial.
2. Install app dependencies and setup environment variables 🔐
To install this project’s dependencies after you’ve cloned the repo, just run:
yarn…at the root of the directory. Then, we need to get our .env file from our .env.example file. To do that run:
cp .env.example .envIn your .env file, you still need to provide INFURA_ENDPOINT_KEY. Contrary to what you might initially think, this variable is actually your PROJECT ID of your Infura app.
If you don’t have an Infura account, you can create one for free! 🆓 🕺

An example view of the Infura dashboard for my redwood-eth-with-fauna app. Copy the PROJECT ID and paste it in your .env file as for INFURA_ENDPOINT_KEY
3. Update the GraphQL schema and run the database migration
In the schema file found by at:
api/prisma/schema.prisma …we need to add a field to the Auction model. This is due to a bug in the code where this field is actually missing from the monorepo. So, we must add it to get our app working!

We are adding line 33, a contentHash field with the type `String` so that our Auctions can be added to our database and then shown to the user.
After that, we need to run a database migration using a Redwood.js command that will automatically update some of our project’s code. (How generous of the Redwood devs to abstract this responsibility from us; this command just works!) To do that, run:
yarn rw db save redwood-eth-with-fauna && yarn rw db upYou should see something like the following if this process was successful.

At this point, you could start the app by running
yarn rw dev…and create, and then mint your first NFT! 🎉 🎉
Note: You may get the following error when minting a new NFT:

If you do, just refresh the page to see your new NFT on the right!
You can also click on the name of your new NFT to view it’s auction details like the one shown below:

You can also notice on your terminal that Redwood updates the API resolver when you navigate to this page.
That’s all for the setup! Unfortunately, I won’t be touching on how to use this part of the UI, but you’re welcome to visit Emanator’s monorepo to learn more.
Now, we want to add Fauna to our app.
Adding Fauna
Before we get to adding Fauna to our Redwood app, let’s make sure to power it down by pressing CTL+C (on macOS). Redwood handles hot reloading for us and will automatically re-render pages as we make edits which can get quite annoying while we make your adjustments. So, we’ll keep our app down for now until we’ve finished adding Fauna.
Next, we want to make sure we have a Fauna secret API key from a Fauna database that we create on Fauna’s dashboard (I will not walk through how to do that, but this helpful article does a good job of covering it!). Once you have copied your key secret, paste it into your .env file by replacing <FAUNA_SECRET_KEY>:

Make sure to leave the quotation marks in place!
Importing GraphQL Schema to Fauna
To import our GraphQL schema of our project to Fauna, we need to first schema stitch our 3 separate schemas together, a process we’ll do manually. Make a new file api/src/graphql/fauna-schema-to-import.gql. In this file, we will add the following:
type Query {
bids: [Bid!]!
auctions: [Auction!]!
auction(address: String!): Auction
web3Auction(address: String!): Web3Auction!
web3User(address: String!, auctionAddress: String!): Web3User!
}
# ------ Auction schema ------
type Auction {
id: Int!
owner: String!
address: String!
name: String!
winLength: Int!
description: String
contentHash: String
createdAt: String!
status: String!
highBid: Int!
generation: Int!
revenue: Int!
bids: [Bid]!
}
input CreateAuctionInput {
address: String!
name: String!
owner: String!
winLength: Int!
description: String!
contentHash: String!
status: String
highBid: Int
generation: Int
}
# Comment out to bypass Fauna `Import your GraphQL schema' error
# type Mutation {
# createAuction(input: CreateAuctionInput!): Auction
# }
# ------ Bids ------
type Bid {
id: Int!
amount: Int!
auction: Auction!
auctionAddress: String!
}
input CreateBidInput {
amount: Int!
auctionAddress: String!
}
input UpdateBidInput {
amount: Int
auctionAddress: String
}
# ------ Web3 ------
type Web3Auction {
address: String!
highBidder: String!
status: String!
highBid: Int!
currentGeneration: Int!
auctionBalance: Int!
endTime: String!
lastBidTime: String!
# Unfortunately, the Fauna GraphQL API does not support custom scalars.
# So, we'll this field from the app.
# pastAuctions: JSON!
revenue: Int!
}
type Web3User {
address: String!
auctionAddress: String!
superTokenBalance: String!
isSubscribed: Boolean!
}Using this schema, we can now import it to our Fauna database.
Also, don’t forget to make the necessary changes to our 3 separate schema files api/src/graphql/auctions.sdl.js, api/src/graphql/bids.sdl.js, and api/src/graphql/web3.sdl.js to correspond to our new Fauna GraphQL schema!! This is important to maintain consistency between our app’s GraphQL schema and Fauna’s.
View Complete Project Diffs — Quick Start section
If you want to take a deep dive and learn the necessary changes required to get this project up and running, great! Head on to the next section!!
Otherwise, if you want to just get up and running quickly, this section is for you.
You can git checkout the `integrating-fauna` branch at the root directory of this project’s repo. To do that, run the following command:
git checkout integrating-faunaThen, run yarn again, for a sanity check:
yarnTo start the app, you can then run:
yarn rw devSteps to add Fauna
Now for some more steps to get our project going!
1. Install faunadb and graphql-request
First, let’s install the Fauna JavaScript driver faunadb and the graphql-request. We will use both of these for our main modifications to our database scripts folder to add Fauna.
To install, run:
yarn workspace api add faunadb graphql-request2. Edit api/src/lib/db.js and api/src/functions/graphql.js
Now, we will replace the PrismaClient instance in api/src/lib/db.js with our Fauna instance. You can delete everything in file and replace it with the following:

Then, we must make a small update to our api/src/functions/graphql.js file like so:

3. Create api/src/lib/fauna-client.js
In this simple file, we will instantiate our client-side instance of the Fauna database with two variables which we will be using in the next step. This file should end up looking like the following:

4. Update our first service under api/src/services/auctions/auctions.js
Here comes the hard part. In order to get our services running, we need to replace all Prisma related commands with commands using an instance of the Fauna client from our fauna-client.js we just created. This part doesn’t seem straightforward initially, but with some deep thought and thinking, all the necessary changes come down to understanding how Fauna’s FQL commands work.
FQL (Fauna Query Language) is Fauna’s native API for querying Fauna. Since FQL is expression-oriented, using it is as simple as chaining several functional commands. Thus, for the first changes in api/services/auctions/auctions.js, we’ll do the following:

To break this down a bit, first, we import the client variables and `db` instance from the proper project file paths. Then, we remove line 11, and replace it with lines 13 – 28 (you can ignore the comments for now, but if you really want to see the rest of these, you can check out the integrating-fauna branch from this project’s repo to see the complete diffs). Here, all we’re doing is using FQL to query the auctions Index of our Fauna Indexes to get all the auctions data from our Fauna database. You can test this out by running console.log(auctionsRaw).
From running that console.log(), we see that we need to do some object destructing to get the data we need to update what was previously line 18:
const auctions = await auctionsRaw.map(async (auction, i) => {Since we dealing with an object, but we want an array, we’ll add the following in the next line after finishing the declaration of const auctionsRaw:

Now we can see that we’re getting the right data format.
Next, let’s update the call instance of `auctionsRaw` to our new auctionsDataObjects:

Here comes the most challenging part of updating this file. We want to update the simple return statement of both the auction and createAuction functions. Actually, the changes we make are actually quite similar. So, let’s make update our auction function like so:

Again, you can ignore the comments, as this comment is just to note the preference return command statement that was there prior to our changes.
All this query says is, “in the auction Collection, find one specific auction that has this address.”
This next step to complete this createAuctin function is admittedly quite hacky. While making this tutorial, I realized that Fauna’s GraphQL API unfortunately does not support custom scalars (you can read more about that under the Limitations section of their GraphQL documentation). This sadly meant that the GraphQL schema of Emanator’s monorepo would not work directly out of the box. In the end, this resulted in having to make many minor changes to get the app to properly run the creation of an auction. So, instead of walking in detail through this section, I will first show you the diff, then briefly summarize the purpose of the changes.

Looking at the green lines of 100 and 101, we can see that the functional commands we’re using here are not that much different; here, we’re just creating a new document in our Auction collection, instead of reading from the Indexes.
Turning back to the data fields of this createAuction function, we can see that we are given an input as argument, which actually refers to the UI input fields of the new NFT auction form on the Home page. Thus, input is an object of six fields, namely address, name, owner, winLength, description, and contentHash. However, the other four fields that are required to fulfill our GraphQL schema for an Auction type are still missing! Therefore, the other variables I created, id, dateTime, status, and highBid are variables I, more or less, hardcoded so that this function could complete successfully.
Lastly, we need to complete the export of the Auction constant. To do that, we’ll make use of the Fauna client once more to make the following changes:

And, we’re finally done with our first service 🎊 , phew!
Completing GraphQL services
By now, you may be feeling a bit tired from these changes from updating the GraphQL services (I know I was while I was trying to learn the necessary changes to make!). So, to save you time getting this app to work, I’ll instead of walking through them entirely, I will share the git diffs again from the integrating-fauna branch that I have already working in the repo. After sharing them, I will summarize the changes that were made.
First file to update is api/src/services/bids/bids.js:

And, updating our last GraphQL service:
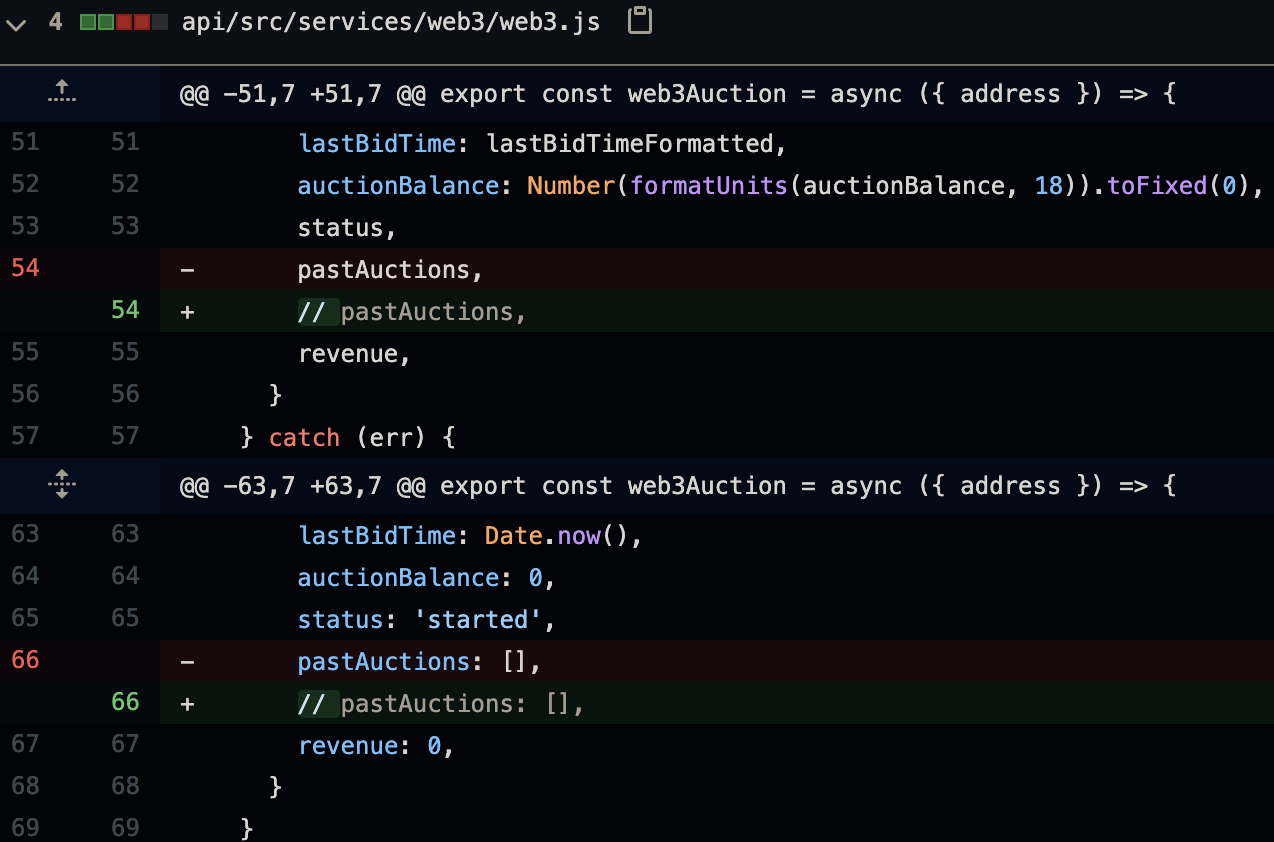
Finally, one final change in web/src/components/AuctionCell/AuctionCell.js:

So, back to Fauna not supporting custom scalars. Since Fauna doesn’t support custom scalars, we had to comment out the pastAuctions field from our web3.js service query (along with commenting it out from our GraphQL schemas).
The last change that was made in web/src/components/AuctionCell/AuctionCell.js is another hacky change to make the newly created NFT address domains (you can navigate to these when you click on the hyperlink of the NFT name, located on the right of the home page after you create a new NFT) clickable without throwing an error. 😄
Conclusion
Finally, when you run:
yarn rw dev…and you create a new token, you can now do so using Fauna!! 🎉🎉🎉🎉
Final notes
There are two caveats. First, you will see this annoying error message appear above the create NFT form after you have created one and confirmed the transaction with MetaMask.

Unfortunately, I couldn’t find a solution for this besides refreshing the page. So, we will do this just like we did with our original Emanator monorepo version.
But when you do refresh the page, you should see your new shiny token displayed on the right! 👏

And, this is with the NFT token data fetched from Fauna! 🙌 🕺 🙌🙌
The second caveat is that the page for a new NFT is still not renderable due to the bug web/src/components/AuctionCell/AuctionCell.js.
This is another issue I couldn’t solve. However, this is where you, the community, can step in! This repo, redwood-eth-with-fauna is openly available on GitHub, along with the (currently) finalized integrating-fauna branch that has a working (as it currently does 😅) version of the Emanator app. So, if you’re really interested in this app and would like to explore how to leverage this app further with Fauna, feel free to fork the project and explore or make changes! I can always be reached on GitHub and am always happy to help you! 😊
That’s all for this tut, and I hope you enjoyed! Feel free to reach out with any questions on GitHub!
The post Building an Ethereum app using Redwood.js and Fauna appeared first on CSS-Tricks.
You can support CSS-Tricks by being an MVP Supporter.
from CSS-Tricks https://ift.tt/3so3Bua
via IFTTT




No comments:
Post a Comment