As a web developer, there is an interesting bit of back and forth that always comes along with setting up a new application. Even using a full stack web framework like Ruby on Rails can be non-trivial to set up and deploy, especially if it’s your first time doing so in a while.
Personally I have always enjoyed being able to dig in and write the actual bit of application logic more so than setting up the apps themselves. Lately I have become a big fan of React applications together with a GraphQL API and storing state with the Apollo library.
Setting up a React application has become very easy in the past few years, but setting up a backend with a GraphQL API? Not so much. So when I was working on a project recently, I decided to look for an easier way to integrate a GraphQL API and was delighted to find FaunaDB.
FaunaDB is a NoSQL database as a service that makes provisioning a GraphQL API an incredibly simple process, and even comes with a free tier. Frankly I was surprised and really impressed with how quickly I was able to go from zero to a working API.
The service also touts its production readiness, with a focus on making scalability much easier than if you were managing your own backend. Although I haven’t explored its more advanced features yet, if it’s anything like my first impression then the prospects and implications of using FaunaDB are quite exciting. For now, I can confirm that for many of my projects, it provides an excellent solution for managing state together with a React application.
While working on my project, I did run into a few configuration issues when making all of the frameworks work together which I think could’ve been addressed with a guide that focuses on walking through standing up an application in its entirety. So in this article, I’m going to do a thorough walkthrough of setting up a small to-do React application on Heroku, then persisting data to that application with FaunaDB using the Apollo library. You can find the full source code here.
Our Application
For this walkthrough, we’re building a to-do list where a user can take the following actions:
- Add a new item
- Mark an item as complete
- Remove an item
From a technical perspective, we’re going to accomplish this by doing the following:
- Creating a React application
- Deploying the application to Heroku
- Provisioning a new FaunaDB database
- Declaring a GraphQL API schema
- Provisioning a new database key
- Configuring Apollo in our React application to interact with our API
- Writing application logic and consume our API to persist information
Here’s a preview of what the final result will look like:

Creating the React Application
First we’ll create a boilerplate React application and make sure it runs. Assuming you have create-react-app installed, the commands to create a new application are:
create-react-app fauna-todo
cd fauna-todo
yarn startAfter which you should be able to head to http://localhost:3000 and see the generated homepage for the application.
Deploying to Heroku
As I mentioned above, deploying React applications has become awesomely easy over the last few years. I’m using Heroku here since it’s been my go-to platform as a service for a while now, but you could just as easily use another service like Netlify (though of course the configuration will be slightly different). Assuming you have a Heroku account and the Heroku CLI installed, then this article shows that you only need a few lines of code to create and deploy a React application.
git init
heroku create -b https://github.com/mars/create-react-app-buildpack.git
git push heroku masterAnd your app is deployed! To view it you can run:
heroku openProvisioning a FaunaDB Database
Now that we have a React app up and running, let’s add persistence to the application using FaunaDB. Head to fauna.com to create a free account. After you have an account, click “New Database” on the dashboard, and enter in a name of your choosing:


Creating an API via GraphQL Schema in FaunaDB
In this example, we’re going to declare a GraphQL schema then use that file to automatically generate our API within FaunaDB. As a first stab at the schema for our to-do application, let’s suppose that there is simply a collection of “Items” with “name” as its sole field. Since I plan to build upon this schema later and like being able to see the schema itself at a glance, I’m going to create a schema.graphql file and add it to the top level of my React application. Here is the content for this file:
type Item {
name: String
}
type Query {
allItems: [Item!]
}If you’re unfamiliar with the concept of defining a GraphQL schema, think of it as a manifest for declaring what kinds of objects and queries are available within your API. In this case, we’re saying that there is going to be an Item type with a name string field and that we are going to have an explicit query allItems to look up all item records. You can read more about schemas in this Apollo article and types in this graphql.org article. FaunaDB also provides a reference document for declaring and importing a schema file.
We can now upload this schema.graphql file and use it to generate a GraphQL API. Head to the FaunaDB dashboard again and click on “GraphQL” then upload your newly created schema file here:

Congratulations! You have created a fully functional GraphQL API. This page turns into a “GraphQL Playground” which lets you interact with your API. Click on the “Docs” tab in the sidebar to see the available queries and mutations.

Note that in addition to our allItems query, FaunaDB has generated the following queries/mutations automatically on our behalf:
findItemByIDcreateItemupdateItemdeleteItem
All of these were derived by declaring the Item type in our schema file. Pretty cool right? Let’s give these queries and mutations a spin to familiarize ourselves with them. We can execute queries and mutations directly in the “GraphQL Playground.” Let’s first run a query for items. Enter this query into the left pane of the playground:
query MyItemQuery {
allItems {
data {
name
}
}
}Then click on the play button to run it:

The result is listed on the right pane, and unsurprisingly returns no results since we haven’t created any items yet. Fortunately createItem was one of the mutations that was automatically generated from the schema and we can use that to populate a sample item. Let’s run this mutation:
mutation MyItemCreation {
createItem(data: { name: "My first todo item" }) {
name
}
}
You can see the result of the mutation in the right pane. It seems like our item was created successfully, but just to double check we can re-run our first query and see the result:

You can see that if we add our first query back to the left pane in the playground that the play button gives you a choice as to which operation you’d like to perform. Finally, note in step 3 of the screenshot above that our item was indeed created successfully.
In addition to running the query above, we can also look in the “Collections” tab of FaunaDB to view the collection directly:

Provisioning a New Database Key
Now that we have the database itself configured, we need a way for our React application to access it.
For the sake of simplicity in this application, this will be done with a secret key that we can add as an environment variable to our React application. We aren’t going to have authentication for individual users. Instead we’ll generate an application key which has permission to create, read, update, and delete items.
Authentication and authorization are substantial topics on their own — if you would like to learn more on how FaunaDB handles them as a follow up exercise to this guide, you can read all about the topic here.
The application key we generate has an associate set of permissions that are grouped together in a “role.” Let’s begin by first defining a role that has permission to perform CRUD operations on items, as well as perform the allItems query. Start by going to the “Security” tab, then clicking on “Manage Roles”:

There are 2 built in roles, admin and server. We could in theory use these roles for our key, but this is a bad idea as those keys would allow whoever has access to this key to perform database level operations such as creating new collections or even destroy the database itself. So instead, let’s create a new role by clicking on “New Custom Role” button:
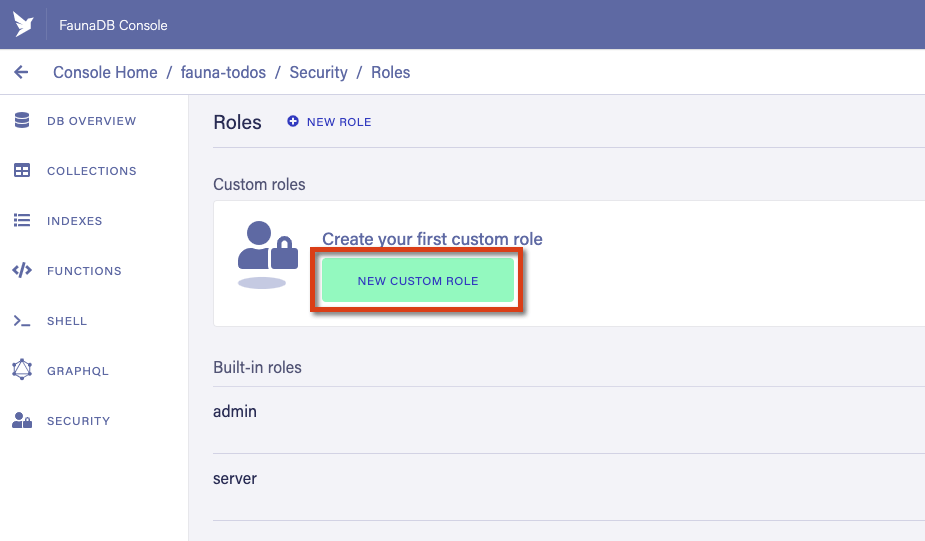
You can name the role whatever you’d like, here we’re using the name ItemEditor and giving the role permission to read, write, create, and delete items — as well as permission to read the allItems index.

Save this role then, head to the “Security” tab and create a new key:

When creating a key, make sure to select “ItemEditor” for the role and whatever name you please:

Next you’ll be presented with your secret key which you’ll need to copy:

In order for React to load the key’s value as an environment variable, create a new file called .env.local which lives at the root level of your React application. In this file, add an entry for the generated key:
REACT_APP_FAUNA_SECRET=fnADzT7kXcACAFHdiKG-lIUWq-hfWIVxqFi4OtTvImportant: Since it’s not good practice to store secrets directly in source control in plain text, make sure that you also have a .gitignore file in your project’s root directory that contains .env.local so that your secrets won’t be added to your git repo and shared with others.
It’s critical that this variable’s name starts with “REACT_APP_” otherwise it won’t be recognized when the application is started. By adding the value to the .env.local file, it will still be loaded for the application when running locally. You’ll have to explicitly stop and restart your application with yarn start in order to see these changes take.
If you’re interested in reading more about how environment variables are loaded in apps created via create-react-app, there is a full explanation here. We’ll cover adding this secret as an environment variable in Heroku later on in this article.
Connecting to FaunaDB in React with Apollo
In order for our React application to interact with our GraphQL API, we need some sort of GraphQL client library. Fortunately for us, the Apollo client provides an elegant interface for making API requests as well as caching and interacting with the results.
To install the relevant Apollo packages we’ll need, run:
yarn add @apollo/client graphql @apollo/react-hooksNow in your src directory of your application, add a new file named client.js with the following content:
import { ApolloClient, InMemoryCache } from "@apollo/client";
export const client = new ApolloClient({
uri: "https://graphql.fauna.com/graphql",
headers: {
authorization: `Bearer ${process.env.REACT_APP_FAUNA_SECRET}`,
},
cache: new InMemoryCache(),
});What we’re doing here is configuring Apollo to make requests to our FaunaDB database. Specifically, the uri makes the request to Fauna itself, then the authorization header indicates that we’re connecting to the specific database instance for the provided key that we generated earlier.
There are 2 important implications from this snippet of code:
- The authorization header contains the key with the “ItemEditor” role, and is currently hard coded to use the same header regardless of which user is looking at our application. If you were to update this application to show a different to-do list for each user, you would need to login for each user and generate a token which could instead be passed in this header. Again, the FaunaDB documentation covers this concept if you care to learn more about it.
- As with any time you add a layer of caching to a system (as we are doing here with Apollo), you introduce the potential to have stale data. FaunaDB’s operations are strongly consistent, and you can configure Apollo’s
fetchPolicyto minimize the potential for stale data. In order to prevent stale reads to our cache, we’ll use a combination of refetch queries and specifying response fields in our mutations.
Next we’ll replace the contents of the home page’s component. Head to App.js and replace its content with:
import React from "react";
import { ApolloProvider } from "@apollo/client";
import { client } from "./client";
function App() {
return (
<ApolloProvider client={client}>
<div style=>
<h3>My Todo Items</h3>
<div>items to get loaded here</div>
</div>
</ApolloProvider>
);
}Note: For this sample application I’m focusing on functionality over presentation, so you’ll see some inline styles. While I certainly wouldn’t recommend this for a production-grade application, I think it does at least demonstrate any added styling in the most straightforward manner within a small demo.
Visit http://localhost:3000 again and you’ll see:

Which contains the hard coded values we’ve set in our jsx above. What we would really like to see however is the to-do item we created in our database. In the src directory, let’s create a component called ItemList which lists out any items in our database:
import React from "react";
import gql from "graphql-tag";
import { useQuery } from "@apollo/react-hooks";
const ITEMS_QUERY = gql`
{
allItems {
data {
_id
name
}
}
}
`;
export function ItemList() {
const { data, loading } = useQuery(ITEMS_QUERY);
if (loading) {
return "Loading...";
}
return (
<ul>
{data.allItems.data.map((item) => {
return <li key={item._id}>{item.name}</li>;
})}
</ul>
);
}Then update App.js to render this new component — see the full commit in this example’s source code to see this step in its entirety. Previewing your app in again, you’ll see that your to-do item has loaded:

Now is a good time to commit your progress in git. And since we’re using Heroku, deploying is a snap:
git push heroku master
heroku openWhen you run heroku open though, you’ll see that the page is blank. If we inspect the network traffic and request to FaunaDB, we’ll see an error about how the database secret is missing:

Which makes sense since we haven’t configured this value in Heroku yet. Let’s set it by going to the Heroku dashboard, selecting your application, then clicking on the “Settings” tab. In there you should add the REACT_APP_FAUNA_SECRET key and value used in the .env.local file earlier. Reusing this key is done for demonstration purposes. In a “real” application, you would probably have a separate database and separate keys for each environment.

If you would prefer to use the command line rather than Heroku’s web interface, you can use the following command and replace the secret with your key instead:
heroku config:set REACT_APP_FAUNA_SECRET=fnADzT7kXcACAFHdiKG-lIUWq-hfWIVxqFi4OtTvImportant: as noted in the Heroku docs, you need to trigger a deploy in order for this environment variable to apply in your app:
git commit — allow-empty -m 'Add REACT_APP_FAUNA_SECRET env var'
git push heroku master
heroku openAfter running this last command, your Heroku-hosted app should appear and load the items from your database.
Adding New To-Do Items
We now have all of the pieces in place for accessing our FaunaDB database both locally and a hosted Heroku environment. Now adding items is as simple as calling the mutation we used in the GraphQL Playground earlier. Here is the code for an AddItem component, which uses a bare bones html form to call the createItem mutation:
import React from "react";
import gql from "graphql-tag";
import { useMutation } from "@apollo/react-hooks";
const CREATE_ITEM = gql`
mutation CreateItem($data: ItemInput!) {
createItem(data: $data) {
_id
}
}
`;
const ITEMS_QUERY = gql`
{
allItems {
data {
_id
name
}
}
}
`;
export function AddItem() {
const [showForm, setShowForm] = React.useState(false);
const [newItemName, setNewItemName] = React.useState("");
const [createItem, { loading }] = useMutation(CREATE_ITEM, {
refetchQueries: [{ query: ITEMS_QUERY }],
onCompleted: () => {
setNewItemName("");
setShowForm(false);
},
});
if (showForm) {
return (
<form
onSubmit={(e) => {
e.preventDefault();
createItem({ variables: { data: { name: newItemName } } });
}}
>
<label>
<input
disabled={loading}
type="text"
value={newItemName}
onChange={(e) => setNewItemName(e.target.value)}
style=
/>
</label>
<input disabled={loading} type="submit" value="Add" />
</form>
);
}
return <button onClick={() => setShowForm(true)}>Add Item</button>;
}After adding a reference to AddItem in our App component, we can verify that adding items works as expected. Again, you can see the full commit in the demo app for a recap of this step.
Deleting New To-Do Items
Similar to how we called the automatically generated AddItem mutation to add new items, we can call the generated DeleteItem mutation to remove items from our list. Here’s what our updated ItemList component looks like after adding this mutation:
import React from "react";
import gql from "graphql-tag";
import { useMutation, useQuery } from "@apollo/react-hooks";
const ITEMS_QUERY = gql`
{
allItems {
data {
_id
name
}
}
}
`;
const DELETE_ITEM = gql`
mutation DeleteItem($id: ID!) {
deleteItem(id: $id) {
_id
}
}
`;
export function ItemList() {
const { data, loading } = useQuery(ITEMS_QUERY);
const [deleteItem, { loading: deleteLoading }] = useMutation(DELETE_ITEM, {
refetchQueries: [{ query: ITEMS_QUERY }],
});
if (loading) {
return <div>Loading...</div>;
}
return (
<ul>
{data.allItems.data.map((item) => {
return (
<li key={item._id}>
{item.name}{" "}
<button
disabled={deleteLoading}
onClick={(e) => {
e.preventDefault();
deleteItem({ variables: { id: item._id } });
}}
>
Remove
</button>
</li>
);
})}
</ul>
);
}Reloading our app and adding another item should result in a page that looks like this:

If you click on the “Remove” button for any item, the DELETE_ITEM mutation is fired and the entire list of items is fired upon completion as specified per the refetchQuery option.
One thing you may have noticed is that in our ITEMS_QUERY, we’re specifying _id as one of the fields we’d like in the result set from our query. This _id field is automatically generated by FaunaDB as a unique identifier for each collection, and should be used when updating or deleting a record.
Marking Items as Complete
This wouldn’t be a fully functional to-do list without the ability to mark items as complete! So let’s add that now. By the time we’re done, we expect the app to look like this:

The first step we need to take is updating our Item schema within FaunaDB since right now the only information we store about an item is its name. Heading to our schema.graphql file, we can add a new field to track the completion state for an item:
type Item {
name: String
isComplete: Boolean
}
type Query {
allItems: [Item!]
}Now head to the GraphQL tab in the FaunaDB console and click on the “Update Schema” link to upload the newly updated schema file.
Note: there is also an “Override Schema” option, which can be used to rewrite your database’s schema from scratch if you’d like. One consideration to make when choosing to override the schema completely is that the data is deleted from your database. This may be fine for a test environment, but a test or production environment would require a proper database migration instead.
Since the changes we’re making here are additive, there won’t be any conflict with the existing schema so we can keep our existing data.
You can view the mutation itself and its expected schema in the GraphQL Playground in FaunaDB:

This tells us that we can call the deleteItem mutation with a data parameter of type ItemInput. As with our other requests, we could test this mutation in the playground if we wanted. For now, we can add it directly to the application. In ItemList.js, let’s add this mutation with this code as outlined in the example repository.
The references to UPDATE_ITEM are the most relevant changes we’ve made. It’s interesting to note as well that we don’t need the refetchQueries parameter for this mutation. When the update mutation returns, Apollo updates the corresponding item in the cache based on its identifier field (_id in this case) so our React component re-renders appropriately as the cache updates.
We now have all of the functionality for an initial version of a to-do application. As a final step, push your branch one more time to Heroku:
git push heroku master
heroku openConclusion
Take a moment to pat yourself on the back! You’ve created a brand-new React application, added persistence at a database level with FaunaDB, and can do deployments available to the entire world with the push of a branch to Heroku.
Now that we’ve covered some of the concepts behind provisioning and interacting with FaunaDB, setting up any similar project in the future is an amazingly fast process. Being able to provision a GraphQL-accessible database in minutes is a dream for me when it comes to spinning up a new project. Not only that, but this is a production grade database that you don’t have to worry about configuring or scaling — and instead get to focus on writing the rest of your application instead of playing the role of a database administrator.
The post A Complete Walkthrough of GraphQL APIs with React and FaunaDB appeared first on CSS-Tricks.
You can support CSS-Tricks by being an MVP Supporter.
from CSS-Tricks https://ift.tt/3jjMjcd
via IFTTT




No comments:
Post a Comment