JavaScript has a variety of built-in popup APIs that display special UI for user interaction. Famously:
alert("Hello, World!");
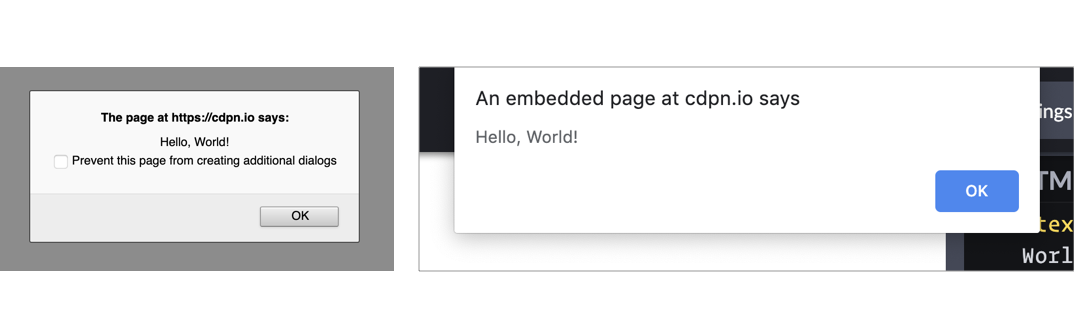
The UI for this varies from browser to browser, but generally you’ll see a little window pop up front and center in a very show-stopping way that contains the message you just passed. Here’s Firefox and Chrome:
Native popups in Firefox (left) and Chrome (right). Note the additional UI preventing additional dialogs in Firefox from triggering it more than once. You can also see how Chrome is pinned to the top of the window.
There is one big problem you should know about up front
JavaScript popups are blocking.
The entire page essentially stops when a popup is open. You can’t interact with anything on the page while one is open — that’s kind of the point of a “modal” but it’s still a UX consideration you should be keenly aware of. And crucially, no other main-thread JavaScript is running while the popup is open, which could (and probably is) unnecessarily preventing your site from doing things it needs to do.
Nine times out of ten, you’d be better off architecting things so that you don’t have to use such heavy-handed stop-everything behavior. Native JavaScript alerts are also implemented by browsers in such a way that you have zero design control. You can’t control *where* they appear on the page or what they look like when they get there. Unless you absolutely need the complete blocking nature of them, it’s almost always better to use a custom user interface that you can design to tailor the experience for the user.
With that out of the way, let’s look at each one of the native popups.
What it’s for: Displaying a simple message or debugging the value of a variable.
How it works: This function takes a string and presents it to the user in a popup with a button with an “OK” label. You can only change the message and not any other aspect, like what the button says.
The Alternative: Like the other alerts, if you have to present a message to the user, it’s probably better to do it in a way that’s tailor-made for what you’re trying to do.
If you’re trying to debug the value of a variable, consider console.log(<code>"`Value of variable:"`, variable); and looking in the console.
window.confirm();
window.confirm("Are you sure?");
<button onclick="confirm('Would you like to play a game?');">Ask Question</button>
let answer = window.confirm("Do you like cats?");
if (answer) {
// User clicked OK
} else {
// User clicked Cancel
}
What it’s for: “Are you sure?”-style messages to see if the user really wants to complete the action they’ve initiated.
How it works: You can provide a custom message and popup will give you the option of “OK” or “Cancel,” a value you can then use to see what was returned.
The Alternative: This is a very intrusive way to prompt the user. As Aza Raskin puts it:
...maybe you don’t want to use a warning at all.”
There are any number of ways to ask a user to confirm something. Probably a clear UI with a <button>Confirm</button> wired up to do what you need it to do.
window.prompt();
window.prompt("What’s your name?");
let answer = window.prompt("What is your favorite color?");
// answer is what the user typed in, if anything
What it’s for: Prompting the user for an input. You provide a string (probably formatted like a question) and the user sees a popup with that string, an input they can type into, and “OK” and “Cancel” buttons.
How it works: If the user clicks OK, you’ll get what they entered into the input. If they enter nothing and click OK, you’ll get an empty string. If they choose Cancel, the return value will be null.
The Alternative: Like all of the other native JavaScript alerts, this doesn’t allow you to style or position the alert box. It’s probably better to use a <form> to get information from the user. That way you can provide more context and purposeful design.
window.onbeforeunload();
window.addEventListener("beforeunload", () => {
// Standard requires the default to be cancelled.
event.preventDefault();
// Chrome requires returnValue to be set (via MDN)
event.returnValue = '';
});
What it’s for: Warn the user before they leave the page. That sounds like it could be very obnoxious, but it isn’t often used obnoxiously. It’s used on sites where you can be doing work and need to explicitly save it. If the user hasn’t saved their work and is about to navigate away, you can use this to warn them. If they *have* saved their work, you should remove it.
How it works: If you’ve attached the beforeunload event to the window (and done the extra things as shown in the snippet above), users will see a popup asking them to confirm if they would like to “Leave” or “Cancel” when attempting to leave the page. Leaving the site may be because the user clicked a link, but it could also be the result of clicking the browser’s refresh or back buttons. You cannot customize the message.
MDN warns that some browsers require the page to be interacted with for it to work at all:
To combat unwanted pop-ups, some browsers don't display prompts created in beforeunload event handlers unless the page has been interacted with. Moreover, some don't display them at all.
The Alternative: Nothing that comes to mind. If this is a matter of a user losing work or not, you kinda have to use this. And if they choose to stay, you should be clear about what they should to to make sure it’s safe to leave.
Accessibility
Native JavaScript alerts used to be frowned upon in the accessibility world, but it seems that screen readers have since become smarter in how they deal with them. According to Penn State Accessibility:
The use of an alert box was once discouraged, but they are actually accessible in modern screen readers.
It’s important to take accessibility into account when making your own modals, but there are some great resources like this post by Ire Aderinokun to point you in the right direction.
General alternatives
There are a number of alternatives to native JavaScript popups such as writing your own, using modal window libraries, and using alert libraries. Keep in mind that nothing we’ve covered can fully block JavaScript execution and user interaction, but some can come close by greying out the background and forcing the user to interact with the modal before moving forward.
You may want to look at HTML’s native <dialog> element. Chris recently took a hands-on look) at it. It’s compelling, but apparently suffers from some significant accessibility issues. I’m not entirely sure if building your own would end up better or worse, since handling modals is an extremely non-trivial interactive element to dabble in. Some UI libraries, like Bootstrap, offer modals but the accessibility is still largely in your hands. You might to peek at projects like a11y-dialog.
Wrapping up
Using built-in APIs of the web platform can seem like you’re doing the right thing — instead of shipping buckets of JavaScript to replicate things, you’re using what we already have built-in. But there are serious limitations, UX concerns, and performance considerations at play here, none of which land particularly in favor of using the native JavaScript popups. It’s important to know what they are and how they can be used, but you probably won’t need them a heck of a lot in production web sites.
Indie and enterprise web developers alike are pushing toward a serverless architecture for modern applications. Serverless architectures typically scale well, avoid the need for server provisioning and most importantly are easy and cheap to set up! And that’s why I believe the next evolution for cloud is serverless because it enables developers to focus on writing applications.
With that in mind, let’s build a REST API (because will we ever stop making these?) using 100% serverless technology.
We’re going to do that with Firebase Cloud Functions and FaunaDB, a globally distributed serverless database with native GraphQL.
Those familiar with Firebase know that Google’s serverless app-building tools also provide multiple data storage options: Firebase Realtime Database and Cloud Firestore. Both are valid alternatives to FaunaDB and are effectively serverless.
But why choose FaunaDB when Firestore offers a similar promise and is available with Google’s toolkit? Since our application is quite simple, it does not matter that much. The main difference is that once my application grows and I add multiple collections, then FaunaDB still offers consistency over multiple collections whereas Firestore does not. In this case, I made my choice based on a few other nifty benefits of FaunaDB, which you will discover as you read along — and FaunaDB’s generous free tier doesn’t hurt, either. 😉
In this post, we’ll cover:
Installing Firebase CLI tools
Creating a Firebase project with Hosting and Cloud Function capabilities
Routing URLs to Cloud Functions
Building three REST API calls with Express
Establishing a FaunaDB Collection to track your (my) favorite video games
Creating FaunaDB Documents, accessing them with FaunaDB’s JavaScript client API, and performing basic and intermediate-level queries
And more, of course!
Set Up A Local Firebase Functions Project
For this step, you’ll need Node v8 or higher. Install firebase-tools globally on your machine:
$ npm i -g firebase-tools
Then log into Firebase with this command:
$ firebase login
Make a new directory for your project, e.g. mkdir serverless-rest-api and navigate inside.
Create a Firebase project in your new directory by executing firebase login.
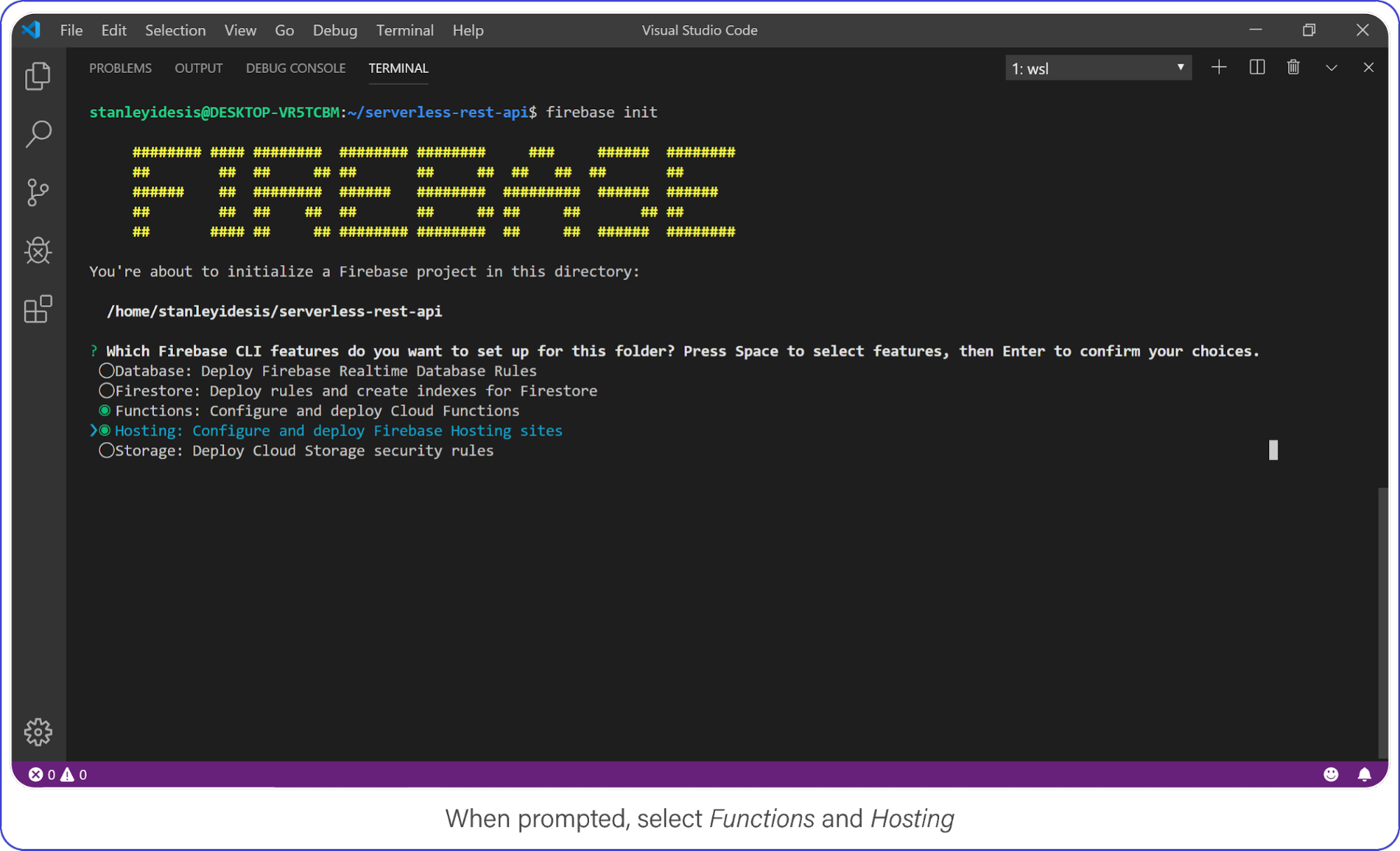
Select Functions and Hosting when prompted.
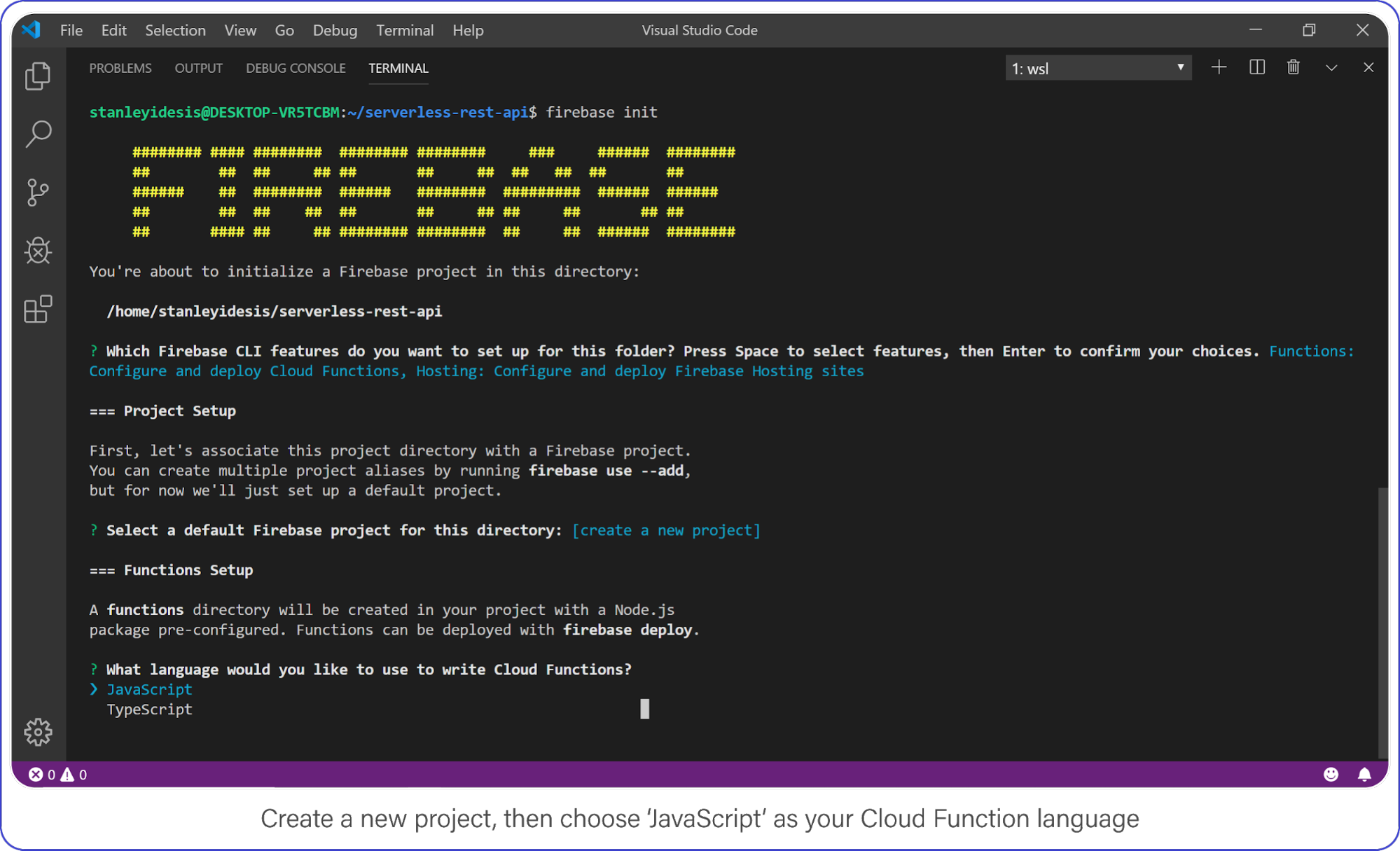
Choose "functions" and "hosting" when the bubbles appear, create a brand new firebase project, select JavaScript as your language, and choose yes (y) for the remaining options.
Create a new project, then choose JavaScript as your Cloud Function language.
Once complete, enter the functions directory, this is where your code lives and where you’ll add a few NPM packages.
Your API requires Express, CORS, and FaunaDB. Install it all with the following:
$ npm i cors express faunadb
Set Up FaunaDB with NodeJS and Firebase Cloud Functions
Before you can use FaunaDB, you need to sign up for an account.
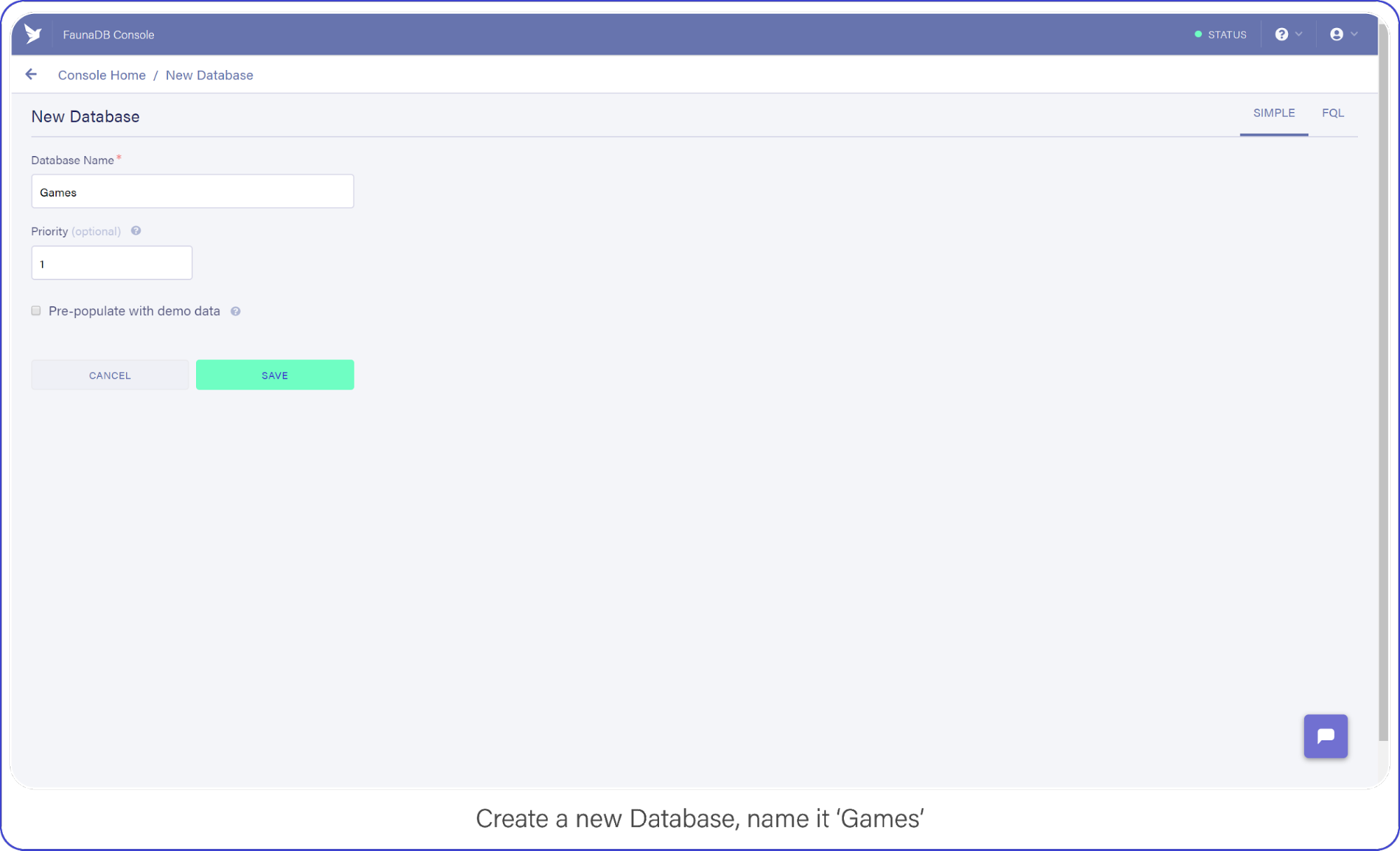
When you’re signed in, go to your FaunaDB console and create your first database, name it "Games."
You’ll notice that you can create databases inside other databases . So you could make a database for development, one for production or even make one small database per unit test suite. For now we only need ‘Games’ though, so let’s continue.
Create a new database and name it "Games."
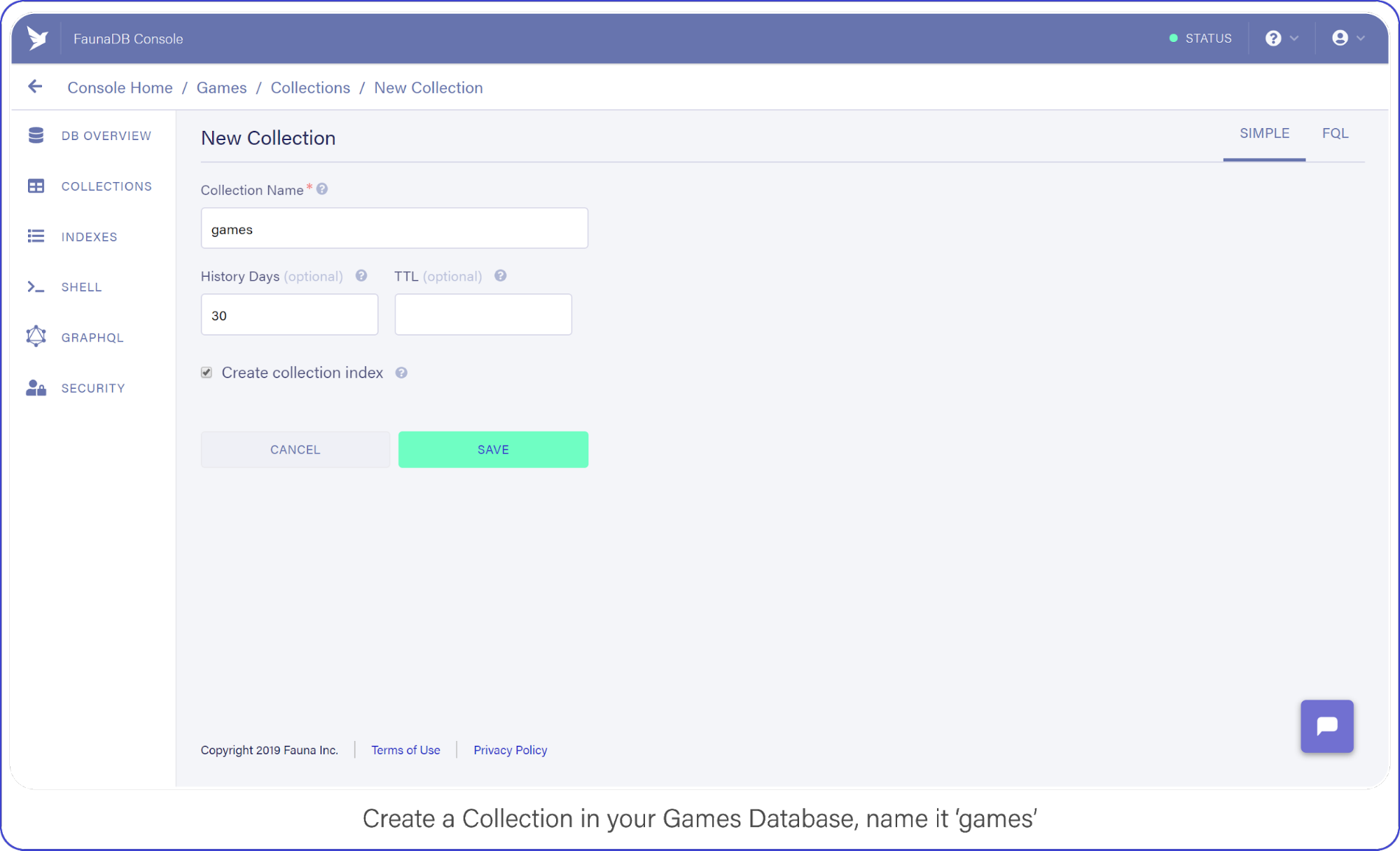
Then tab over to Collections and create your first Collection named ‘games’. Collections will contain your documents (games in this case) and are the equivalent of a table in other databases— don’t worry about payment details, Fauna has a generous free-tier, the reads and writes you perform in this tutorial will definitely not go over that free-tier. At all times you can monitor your usage in the FaunaDB console.
For the purpose of this API, make sure to name your collection ‘games’ because we’re going to be tracking your (my) favorite video games with this nerdy little API.
Create a Collection in your Games Database and name it "Games."
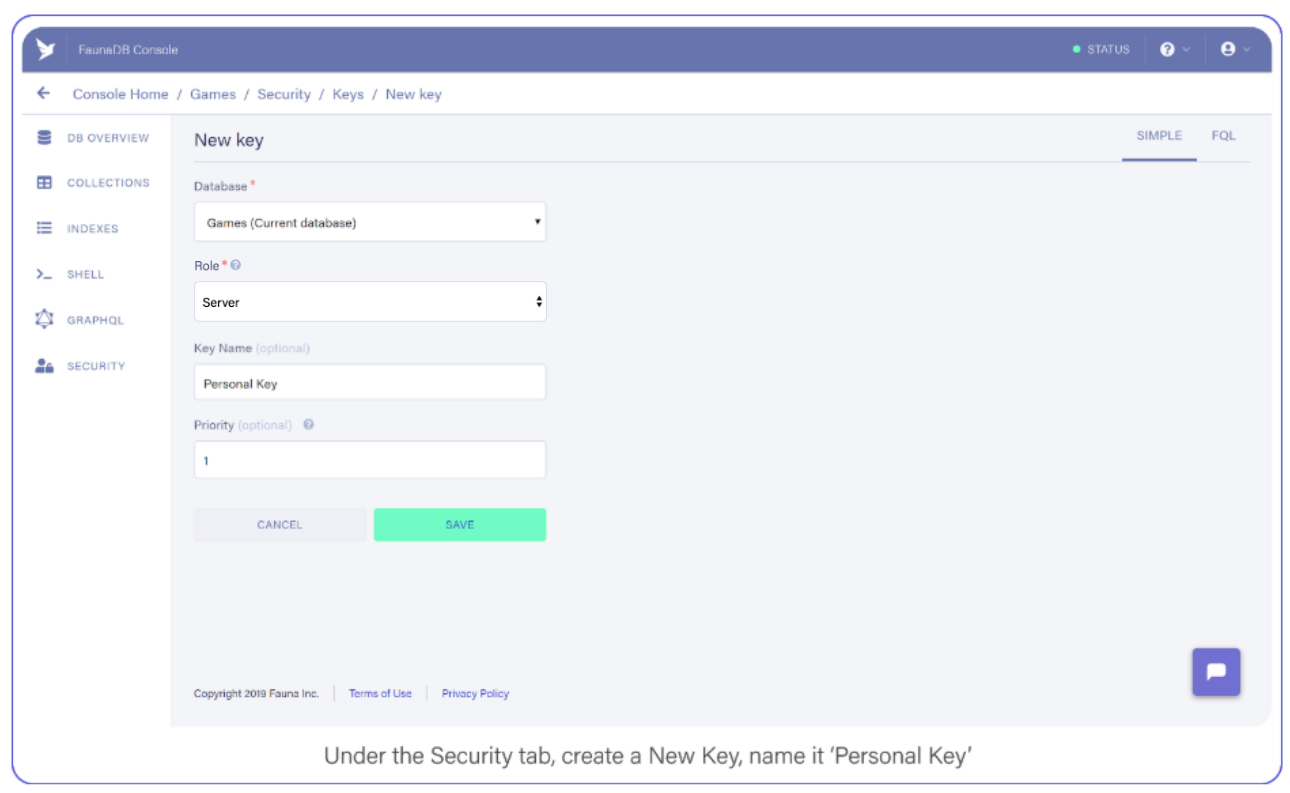
Tab over to Security, and create a new Key and name it "Personal Key." There are 3 different types of keys, Admin/Server/Client. Admin key is meant to manage multiple databases, A Server key is typically what you use in a backend which allows you to manage one database. Finally a client key is meant for untrusted clients such as your browser. Since we’ll be using this key to access one FaunaDB database in a serverless backend environment, choose ‘Server key’.
Under the Security tab, create a new Key. Name it Personal Key.
Save the key somewhere, you’ll need it shortly.
Build an Express REST API with Firebase Functions
Firebase Functions can respond directly to external HTTPS requests, and the functions pass standard Node Request and Response objects to your code — sweet. This makes Google’s Cloud Function requests accessible to middleware such as Express.
Open index.js inside your functions directory, clear out the pre-filled code, and add the following to enable Firebase Functions:
This creates a cloud function named, “api” and passes all requests directly to your api express server.
Routing an API URL to a Firebase HTTPS Cloud Function
If you deployed right now, your function’s public URL would be something like this: https://project-name.firebaseapp.com/api. That’s a clunky name for an access point if I do say so myself (and I did because I wrote this... who came up with this useless phrase?)
To remedy this predicament, you will use Firebase’s Hosting options to re-route URL globs to your new function.
Open firebase.json and add the following section immediately below the "ignore" array:
This setting assigns all /api/v1/... requests to your brand new function, making it reachable from a domain that humans won’t mind typing into their text editors.
With that, you’re ready to test your API. Your API that does... nothing!
Respond to API Requests with Express and Firebase Functions
Before you run your function locally, let’s give your API something to do.
Add this simple route to your index.js file right above your export statement:
Save your index.js fil, open up your command line, and change into the functions directory.
If you installed Firebase globally, you can run your project by entering the following: firebase serve.
This command runs both the hosting and function environments from your machine.
If Firebase is installed locally in your project directory instead, open package.json and remove the --only functions parameter from your serve command, then run npm run serve from your command line.
Visit localhost:5000/api/v1/ in your browser. If everything was set up just right, you will be greeted by a gif from one of my favorite movies.
And if it’s not one of your favorite movies too, I won’t take it personally but I will say there are other tutorials you could be reading, Bethany.
Now you can leave the hosting and functions emulator running. They will automatically update as you edit your index.js file. Neat, huh?
FaunaDB Indexing
To query data in your games collection, FaunaDB requires an Index.
Indexes generally optimize query performance across all kinds of databases, but in FaunaDB, they are mandatory and you must create them ahead of time.
As a developer just starting out with FaunaDB, this requirement felt like a digital roadblock.
"Why can’t I just query data?" I grimaced as the right side of my mouth tried to meet my eyebrow.
I had to read the documentation and become familiar with how Indexes and the Fauna Query Language (FQL) actually work; whereas Cloud Firestore creates Indexes automatically and gives me stupid-simple ways to access my data. What gives?
Typical databases just let you do what you want and if you do not stop and think: : "is this performant?" or “how much reads will this cost me?” you might have a problem in the long run. Fauna prevents this by requiring an index whenever you query.
As I created complex queries with FQL, I began to appreciate the level of understanding I had when I executed them. Whereas Firestore just gives you free candy and hopes you never ask where it came from as it abstracts away all concerns (such as performance, and more importantly: costs).
Basically, FaunaDB has the flexibility of a NoSQL database coupled with the performance attenuation one expects from a relational SQL database.
We’ll see more examples of how and why in a moment.
As with other NoSQL databases, the documents are JSON-style text blocks with the exception of a few Fauna-specific objects (such as Date used in the "release_date" field).
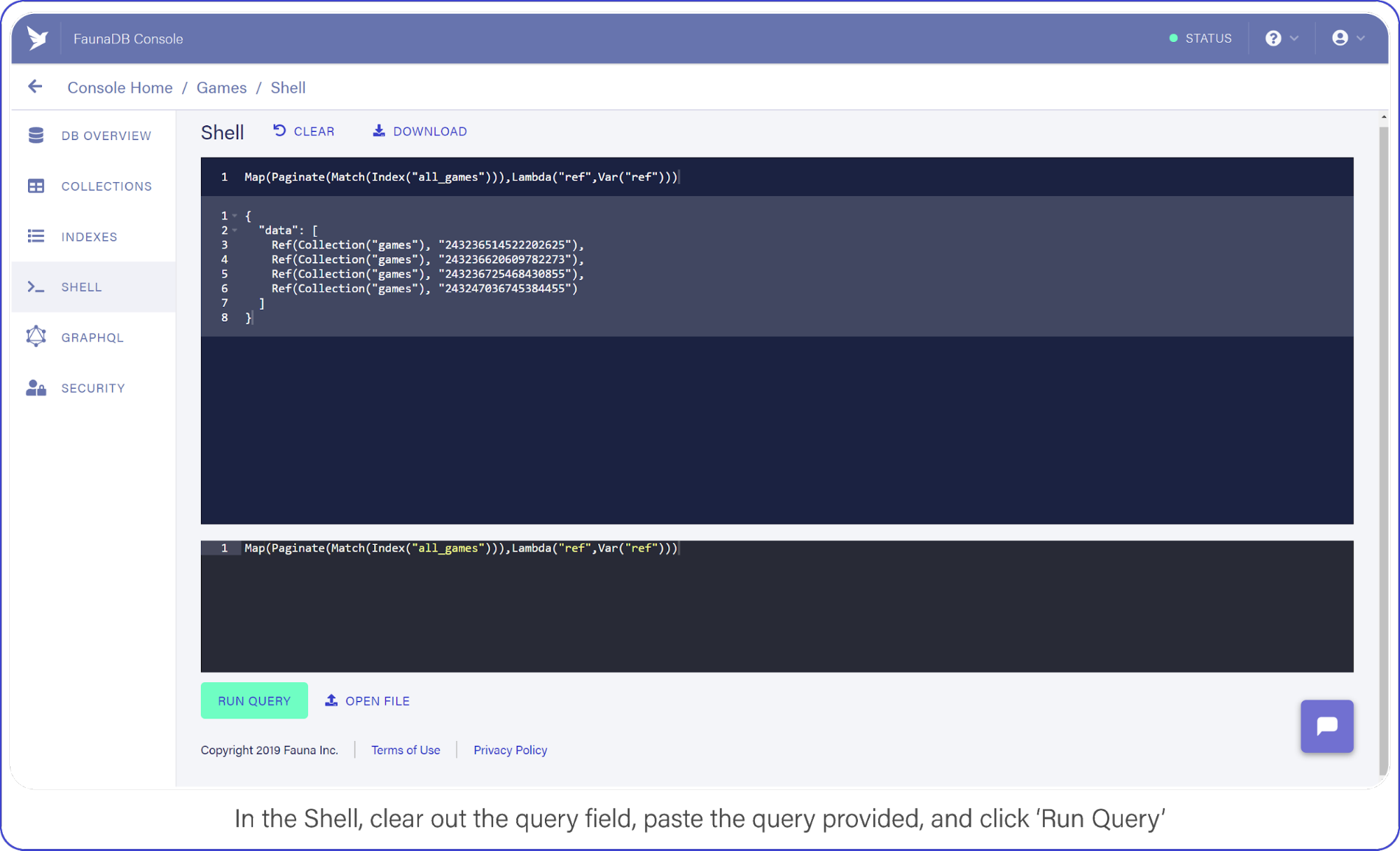
Now switch to the Shell area and clear your query. Paste the following:
And click the "Run Query" button. You should see a list of three items: references to the documents you created a moment ago.
In the Shell, clear out the query field, paste the query provided, and click "Run Query."
It’s a little long in the tooth, but here’s what the query is doing.
Index("all_games") creates a reference to the all_games index which Fauna generated automatically for you when you established your collection.These default indexes are organized by reference and return references as values. So in this case we use the Match function on the index to return a Set of references. Since we do not filter anywhere, we will receive every document in the ‘games’ collection.
The set that was returned from Match is then passed to Paginate. This function as you would expect adds pagination functionality (forward, backward, skip ahead). Lastly, you pass the result of Paginate to Map, which much like its software counterpart lets you perform an operation on each element in a Set and return an array, in this case it is simply returning ref (the reference id).
As we mentioned before, the default index only returns references. The Lambda operation that we fed to Map, pulls this ref field from each entry in the paginated set. The result is an array of references.
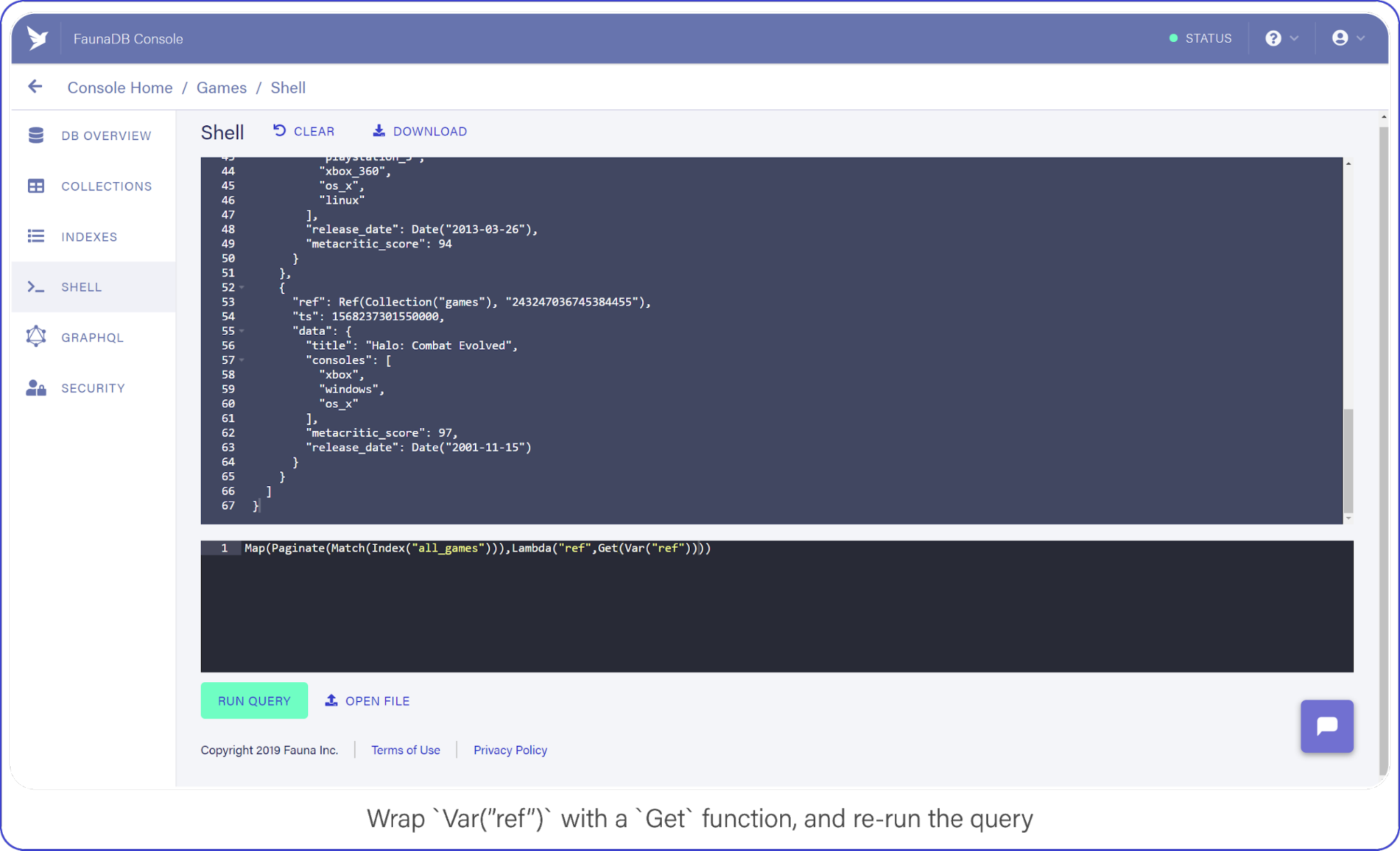
Now that you have a list of references, you can retrieve the data behind the reference by using another function: Get.
Wrap Var("ref") with a Get call and re-run your query, which should look like this:
You perform a Create, pass in your collection, and include data fields that come straight from the body of the request.
client.query returns a Promise, the success-state of which provides a reference to the newly-created document.
And to make sure it’s working, you return the reference to the caller. Let’s see it in action.
Test Firebase Functions Locally with Postman and cURL
Use Postman or cURL to make the following request against localhost:5000/api/v1/ to add Halo: Combat Evolved to your list of games (or whichever Halo is your favorite but absolutely not 4, 5, Reach, Wars, Wars 2, Spartan...)
If everything went right, you should see a reference coming back with your request and a new document show up in your FaunaDB console.
Now that you have some data in your games collection, let’s learn how to retrieve it.
Retrieve FaunaDB Records Using a REST API Request
Earlier, I mentioned that every FaunaDB query requires an Index and that Fauna prevents you from doing inefficient queries. Since our next query will return games filtered by a game console, we can’t simply use a traditional `where` clause since that might be inefficient without an index. In Fauna, we first need to define an index that allows us to filter.
To filter, we need to specify which terms we want to filter on. And by terms, I mean the fields of document you expect to search on.
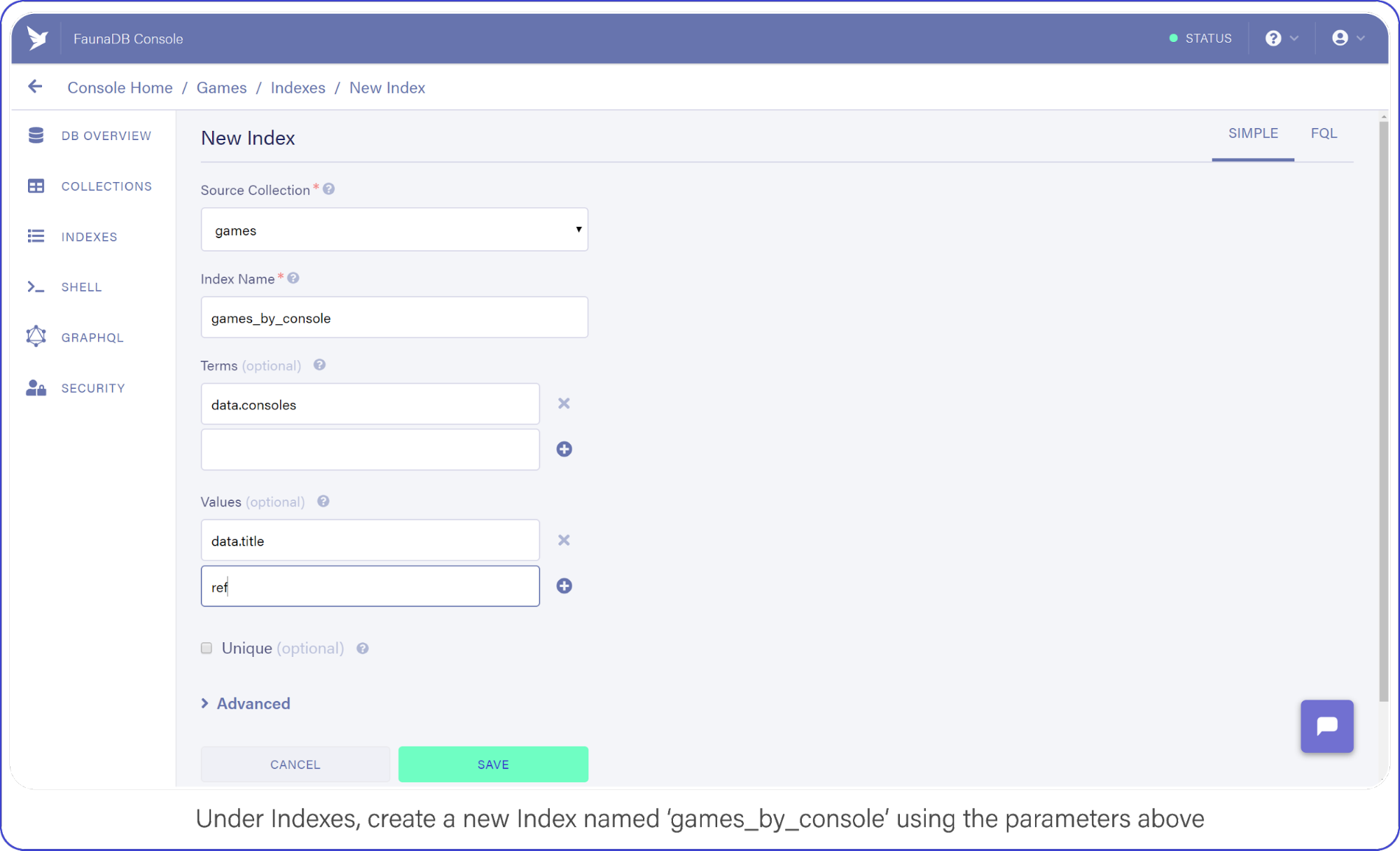
Navigate to Indexes in your FaunaDB Console and create a new one.
Name it games_by_console, set data.consoles as the only term since we will filter on the consoles. Then set data.title and ref as values. Values are indexed by range, but they are also just the values that will be returned by the query. Indexes are in that sense a bit like views, you can create an index that returns a different combination of fields and each index can have different security.
To minimize request overhead, we’ve limited the response data (e.g. values) to titles and the reference.
Your screen should resemble this one:
Under indexes, create a new index named games_by_console using the parameters above.
Click "Save" when you’re ready.
With your Index prepared, you can draft up your next API call.
I chose to represent consoles as a directory path where the console identifier is the sole parameter, e.g. /api/v1/console/playstation_3, not necessarily best practice, but not the worst either — come on now.
This query looks similar to the one you used in your SHELL to retrieve all games, but with a slight modification.This query looks similar to the one you used in your SHELL to retrieve all games, but with a slight modification. Note how your Match function now has a second parameter (req.params.name.toLowerCase()) which is the console identifier that was passed in through the URL.
The Index you made a moment ago, games_by_console, had one Term in it (the consoles array), this corresponds to the parameter we have provided to the match parameter. Basically, the Match function searches for the string you pass as its second argument in the index. The next interesting bit is the Lambda function. Your first encounter with Lamba featured a single string as Lambda’s first argument, “ref.”
However, the games_by_console Index returns two fields per result, the two values you specified earlier when you created the Index (data.title and ref). So basically we receive a paginated set containing tuples of titles and references, but we only need titles. In case your set contains multiple values, the parameter of your lambda will be an array. The array parameter above (`['title', 'ref']`) says that the first value is bound to the text variable title and the second is bound to the variable ref. text parameter. These variables can then be retrieved again further in the query by using Var(‘title’). In this case, both “title” and “ref,” were returned by the index and your Map with Lambda function maps over this list of results and simply returns only the list of titles for each game.
In fauna, the composition of queries happens before they are executed. When you write var q = q.Match(q.Index('games_by_console'))), the variable just contains a query but no query was executed yet. Only when you pass the query to client.query(q) to be executed, it will execute. You can even pass javascript variables in other Fauna FQL functions to start composing queries. his is a big benefit of querying in Fauna vs the chained asynchronous queries required of Firestore. If you ever have tried to generate very complex queries in SQL dynamically, then you will also appreciate the composition and less declarative nature of FQL.
Neat, huh? But Match only returns documents whose fields are exact matches, which doesn’t help the user looking for a game whose title they can barely recall.
Although Fauna does not offer fuzzy searching via indexes (yet), we can provide similar functionality by making an index on all words in the string. Or if we want really flexible fuzzy searching we can use the filter syntax. Note that its is not necessarily a good idea from a performance or cost point of view… but hey, we’ll do it because we can and because it is a great example of how flexible FQL is!
Filtering FaunaDB Documents by Search String
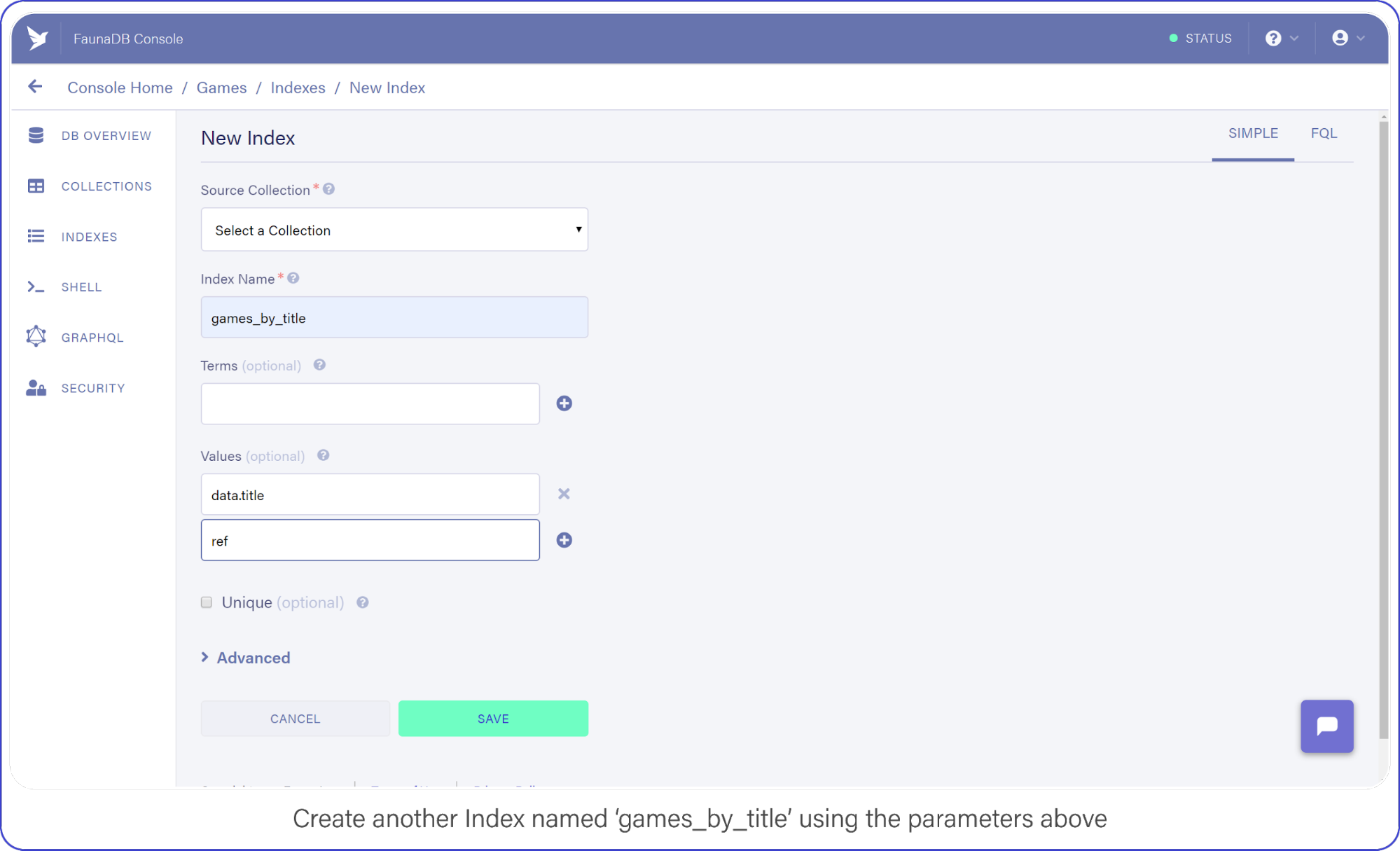
The last API call we are going to construct will let users find titles by name. Head back into your FaunaDB Console, select INDEXES and click NEW INDEX. Name the new Index, games_by_title and leave the Terms empty, you won’t be needing them.
Rather than rely on Match to compare the title to the search string, you will iterate over every game in your collection to find titles that contain the search query.
Remember how we mentioned that indexes are a bit like views. In order to filter on title , we need to include `data.title` as a value returned by the Index. Since we are using Filter on the results of Match, we have to make sure that Match returns the title so we can work with it.
Add data.title and ref as Values, compare your screen to mine:
Create another index called games_by_title using the parameters above.
Click "Save" when you’re ready.
Back in index.js, add your fourth and final API call:
Big breath because I know there are many brackets (Lisp programmers will love this) , but once you understand the components, the full query is quite easy to understand since it’s basically just like coding.
Beginning with the first new function you spot, Filter. Filter is again very similar to the filter you encounter in programming languages. It reduces an Array or Set to a subset based on the result of a Lambda function.
In this Filter, you exclude any game titles that do not contain the user’s search query.
You do that by comparing the result of FindStr (a string finding function similar to JavaScript’s indexOf) to -1, a non-negative value here means FindStr discovered the user’s query in a lowercase-version of the game’s title.
And the result of this Filter is passed to Map, where each document is retrieved and placed in the final result output.
Now you may have thought the obvious: performing a string comparison across four entries is cheap, 2 million…? Not so much.
This is an inefficient way to perform a text search, but it will get the job done for the purpose of this example. (Maybe we should have used ElasticSearch or Solr for this?) Well in that case, FaunaDB is quite perfect as central system to keep your data safe and feed this data into a search engine thanks to the temporal aspect which allows you to ask Fauna: “Hey, give me the last changes since timestamp X?”. So you could setup ElasticSearch next to it and use FaunaDB (soon they have push messages) to update it whenever there are changes. Whoever did this once knows how hard it is to keep such an external search up to date and correct, FaunaDB makes it quite easy.
Don’t You Dare Forget This One Firebase Optimization
A lot of Firebase Cloud Functions code snippets make one terribly wrong assumption: that each function invocation is independent of another.
In reality, Firebase Function instances can remain "hot" for a short period of time, prepared to execute subsequent requests.
This means you should lazy-load your variables and cache the results to help reduce computation time (and money!) during peak activity, here’s how:
let functions, admin, faunadb, q, client, express, cors, api
if (typeof api === 'undefined') {
... // dump the existing code here
}
exports.api = functions.https.onRequest(api)
Deploy Your REST API with Firebase Functions
Finally, deploy both your functions and hosting configuration to Firebase by running firebase deploy from your shell.
Without a custom domain name, refer to your Firebase subdomain when making API requests, e.g. https://{project-name}.firebaseapp.com/api/v1/.
What Next?
FaunaDB has made me a conscientious developer.
When using other schemaless databases, I start off with great intentions by treating documents as if I instantiated them with a DDL (strict types, version numbers, the whole shebang).
While that keeps me organized for a short while, soon after standards fall in favor of speed and my documents splinter: leaving outdated formatting and zombie data behind.
By forcing me to think about how I query my data, which Indexes I need, and how to best manipulate that data before it returns to my server, I remain conscious of my documents.
To aid me in remaining forever organized, my catalog (in FaunaDB Console) of Indexes helps me keep track of everything my documents offer.
And by incorporating this wide range of arithmetic and linguistic functions right into the query language, FaunaDB encourages me to maximize efficiency and keep a close eye on my data-storage policies. Considering the affordable pricing model, I’d sooner run 10k+ data manipulations on FaunaDB’s servers than on a single Cloud Function.
MozCon 2019 was an absolute blast. There were endless snacks. There were Roger hugs. There were networking opportunities and Birds of a Feather tables and search epiphanies galore. And there were a ton of folks in our community who watched it all unfold from the perspective of a Twitter hashtag — fun to follow along with, but not quite the same impact as seeing the talks unfold in real-time.
If you're still wishing you could've joined us in Seattle this past July, you’ll be happy to know that you can recreate the MozCon experience from the comfort of your home or office (or your home office, but hopefully not your office-home — seriously, Karen, the quarterly reports will still be there in the morning!).
Yep, you got it: the MozCon 2019 Video Bundle is available for your purchasing and viewing pleasure!
For those of you who attended in-person, good news: you've already got access! The video bundle is always included in the price of your MozCon ticket, so you can relive your three jam-packed days of learning as many times as you want — and if you aren't too bummed that they already made you share your MozCon swag with them, be sure to share the vids with your team!
For the rest of us, the video bundle lets us enjoy the presentations at our own pace. It's condensed MozCon-caliber information in a neat, on-demand package that you can — have we mentioned this? — share with your team. Seriously, we think they'll like it. We were humbled to host some of the very brightest minds in SEO and digital marketing on our stage. With topics ranging from content marketing to technical SEO, PPC to local SEO, and just about everything in between, there are presentations to inspire just about any role in marketing (and your web dev just might be interested in a few talks, too).
What's covered in the videos:
The Golden Age of Search, Sarah Bird
Web Search 2019: The Essential Data Marketers Need, Rand Fishkin
Human > Machine > Human: Understanding Human-Readable Quality Signals and Their Machine-Readable Equivalents, Ruth Burr Reedy
Improved Reporting & Analytics Within Google Tools, Dana DiTomaso
Local Market Analytics: The Challenges and Opportunities, Rob Bucci
Keywords Aren't Enough: How to Uncover Content Ideas Worth Chasing, Ross Simmonds
How to Supercharge Link Building with a Digital PR Newsroom, Shannon McGuirk
From Zero to Local Ranking Hero, Darren Shaw
Esse Quam Videri: When Faking it is Harder than Making It, Russ Jones
Building a Discoverability Powerhouse: Lessons From Merging an Organic, Paid, & Content Practice, Heather Physioc
Brand Is King: How to Rule in the New Era of Local Search, Mary Bowling
Making Memories: Creating Content People Remember, Casie Gillette
20 Years in Search & I Don't Trust My Gut or Google, Wil Reynolds
Super-Practical Tips for Improving Your Site's E-A-T, Marie Haynes
Fixing the Indexability Challenge: A Data-Based Framework, Areej AbuAli
What Voice Means for Search Marketers: Top Findings from the 2019 Report, Christi Olson
Redefining Technical SEO, Paul Shapiro
How Many Words Is a Question Worth?, Dr. Peter J. Meyers
Fraggles, Mobile-First Indexing, & the SERP of the Future, Cindy Krum
Killer E-commerce CRO and UX Wins Using A SEO Crawler, Luke Carthy
Content, Rankings, and Lead Generation: A Breakdown of the 1% Content Strategy, Andy Crestodina
Running Your Own SEO Tests: Why It Matters & How to Do It Right, Rob Ousbey
Dark Helmet's Guide to Local Domination with Google Posts and Q&A, Greg Gifford
How to Audit for Inclusive Content, Emily Triplett Lentz
Factors that Affect the Local Algorithm that Don't Impact Organic, Joy Hawkins
Featured Snippets: Essentials to Know & How to Target, Britney Muller
What you’ll get:
For just $299, you'll get all of the MozCon education and inspiration with none of the air travel or traffic. The bundle includes:
27 full-length presentation videos chock full of leading SEO innovations, thought leadership, and tips & tricks
Instant downloads and streaming to your computer, tablet, or mobile device
Downloadable slide decks for all presentations
If we could include a download of a Top Pot doughnut and some piping hot Starbucks, we would in a heartbeat. Alas, they don't have the technology for that... yet.
Free preview - Running Your Own SEO Tests: Why It Matters & How to Do It Right by Rob Ousbey
Speaking of doughnuts, we wouldn't expect you to buy a dozen sweet treats without taking a little taste first to see if you like 'em. It's important to know that your doughnuts are both delicious, shareable, and relevant to your everyday work as an SEO — almost exactly like the MozCon video bundle. And just like the feeling of warmth and goodwill you receive when you come back to the office with a fragrant baker's dozen, your teammates will thank you when you've got twenty-seven highly actionable talks to share with them — presentations that'll hone your skills and level up your understanding of modern SEO and digital marketing.
That's why we've released a talk we're super proud of as your free preview of all the juicy goodness you can look forward to in the video bundle: Running Your Own SEO Tests: Why It Matters & How to Do It Right, presentedby our very own Rob Ousbey.
Google's algorithms have undergone significant changes in recent years. Traditional ranking signals don't hold the same sway they used to, and they're being usurped by factors like UX and brand that are becoming more important than ever before. What's an SEO to do? The answer lies in testing. Sharing original data and results from clients, Rob highlights the necessity of testing, learning, and iterating your work, from traditional UX testing to weighing the impact of technical SEO changes, tweaking on-page elements, and changing up content on key pages. Actionable processes and real-world results abound in this thoughtful presentation on why you should be testing SEO changes, how and where to run them, and what kinds of tests you ought to consider for your circumstances.
Gather the team, grab some snacks, and get ready to binge these presentations Netflix-Original-Series-style.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
from The Moz Blog https://ift.tt/36gd1gf
via IFTTT
So much care and planning has gone into creating the web platform, to ensure that even as new features are added, they’re added in a way that doesn’t break the web for anyone using an older device or browser. Can you say the same for any framework out there? I don’t mean that to be perceived as throwing shade (as the kids say). Building the actual web platform requires a deeper level of commitment to these sorts of things out of necessity.
The platform (meaning using standard features built into browsers) might not have everything you need (it often won't) and using those features will bring long-term resiliency to what you build in a way that a framework may not. The web evolves and very likely won't break things. Frameworks evolve and very likely will break things.
CSS allows you to create dynamic layouts and interfaces on the web, but as a language, it is static: once a value is set, it cannot be changed. The idea of randomness is off the table. Generating random numbers at runtime is the territory of JavaScript, not so much CSS. Or is it? If we factor in a little user interaction, we actually can generate some degree of randomness in CSS. Let’s take a look!
Randomization from other languages
There are ways to get some "dynamic randomization" using CSS variables as Robin Rendle explains in an article on CSS-Tricks. But these solutions are not 100% CSS, as they require JavaScript to update the CSS variable with the new random value.
We can use preprocessors such as Sass or Less to generate random values, but once the CSS code is compiled and exported, the values are fixed and the randomness is lost. As Jake Albaugh explains:
random in sass is like randomly choosing the name of a main character in a story. it's only random when written. it doesn't change.
In the past, I've developed simple CSS-only apps such as a trivia game, a Simon game, and a magic trick. But I wanted to do something a little bit more complicated. I'll leave a discussion about the validity, utility, or practicality of creating these CSS-only snippets for a later time.
Based on the premise that some board games could be represented as Finite State Machines (FSM), they could be represented using HTML and CSS. So I started developing a game of Snakes and Ladders (aka Chutes and Ladders). It is a simple game. The goal is to advance a pawn from the beginning to the end of the board by avoiding the snakes and trying to go up the ladders.
The project seemed feasible, but there was something that I was missing: rolling dice!
The roll of dice (along with the flip of a coin) are universally recognized for randomization. You roll the dice or flip the coin, and you get an unknown value each time.
Simulating a random dice roll
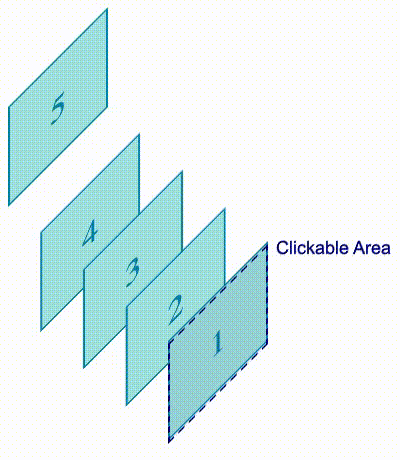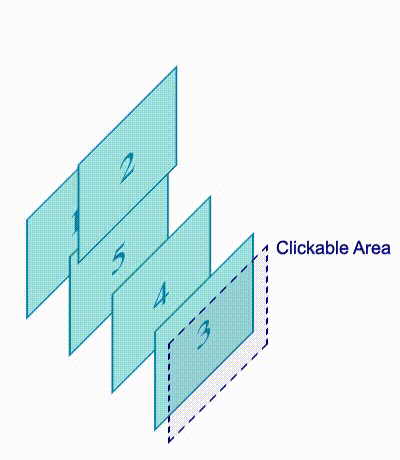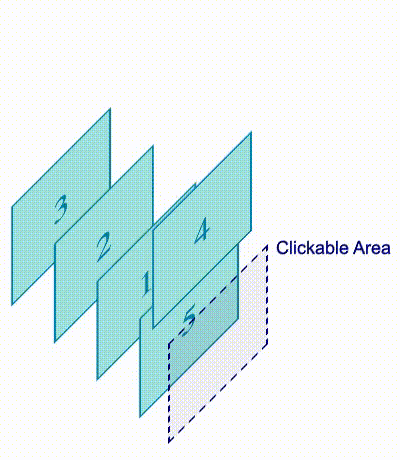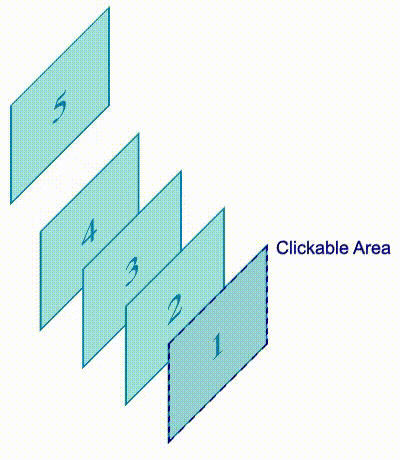
I was going to superimpose layers with labels, and use CSS animations to "rotate" and exchange which layer was on top. Something like this:
Simulation of how the layers animate on a browser
The code to mimic this randomization is not excessively complicated and can be achieved with an animation and different animation delays:
/* The highest z-index is the numbers of sides in the dice */
@keyframes changeOrder {
from { z-index: 6; }
to { z-index: 1; }
}
/* All the labels overlap by using absolute positioning */
label {
animation: changeOrder 3s infinite linear;
background: #ddd;
cursor: pointer;
display: block;
left: 1rem;
padding: 1rem;
position: absolute;
top: 1rem;
user-select: none;
}
/* Negative delay so all parts of the animation are in motion */
label:nth-of-type(1) { animation-delay: -0.0s; }
label:nth-of-type(2) { animation-delay: -0.5s; }
label:nth-of-type(3) { animation-delay: -1.0s; }
label:nth-of-type(4) { animation-delay: -1.5s; }
label:nth-of-type(5) { animation-delay: -2.0s; }
label:nth-of-type(6) { animation-delay: -2.5s; }
The animation has been slowed down to allow easier interaction (but still fast enough to see the roadblock explained below). The pseudo-randomness is clearer, too.
But then I hit a roadblock: I was getting random numbers, but sometimes, even when I was clicking on my "dice," it was not returning any value.
I tried increasing the times in the animation, and that seemed to help a bit, but I was still having some unexpected values.
That's when I did what most developers do when they find a roadblock they cannot resolve just by searching online: I asked other developers for help in the form of a StackOverflow question.
To simplify a little, the problem was that the browser only triggers the click/press event when the element that is active on mouse down is the same element that is active on mouse up.
Because of the rotating animation, the top label on mouse down was not the top label on mouse up, unless I did it fast or slow enough for the animation to circle around. That's why increasing the animation times hid these issues.
The solution was to apply a position of "static" to break the stacking context, and use a pseudo-element like ::before or ::after with a higher z-index to occupy its place. This way, the active label would always be on top when the mouse went up.
/* The active tag will be static and moved out of the window */
label:active {
margin-left: 200%;
position: static;
}
/* A pseudo-element of the label occupies all the space with a higher z-index */
label:active::before {
content: "";
position: absolute;
top: 0;
right: 0;
left: 0;
bottom: 0;
z-index: 10;
}
Here is the code with the solution with a faster animation time:
After making this change, the one thing left was to create a small interface to draw a fake dice to click, and the CSS Snakes and Ladders was completed.
This technique has some obvious inconveniences
It requires user input: a label must be clicked to trigger the "random number generation."
It doesn't scale well: it works great with small sets of values, but it is a pain for large ranges.
It’s not really random, but pseudo-random: a computer could easily detect which value would be generated in each moment.
But on the other hand, it is 100% CSS (no need for preprocessors or other external helpers) and, for a human user, it can look 100% random.
And talking about hands... This method can be used not only for random numbers but for random anything. In this case, we used it to "randomly" pick the computer choice in a Rock-Paper-Scissors game:
Accessibility is our job. We hear it all the time. But the truth is that it often takes a back seat to competing priorities, deadlines, and decisions from above. How can we solve that?
That's where An Event Apart comes in. Making sites inclusive by design is just one of the many topics covered over three full days of sessions designed to inspire you and level up your skills while learning from 17 of today's most talented front-end professionals.
And at An Event Apart, you don’t just learn from the best, you interact with them — at lunch, between sessions, and at the famous first-night Happy Hour party. Web design is more challenging than ever. Attend An Event Apart to be ready for anything the industry throws at you.
CSS-Tricks readers save $100 off any two or three days with code AEACP.
Can franchises make good digital marketing agency clients? There are almost 750,000 of them in the US alone, employing some 9 million Americans. Chances are good you’ll have the opportunity to market a business with this specialized model at some point. In this structure:
The Franchisor grants permission to others to operate under its trademark, selling approved goods and services supported by an operating system and marketing.
The Franchisee is the person or group paying the franchisor for the right to use the trademark and the benefits of the operating system and marketing.
Seems simple enough. But it’s this structure that gives franchise marketing its unique complexities. For your agency, the challenge is that you can’t enter these marketing relationships equipped solely with your knowledge of corporate or local search marketing.
You need to deeply understand the setup to avoid bewilderment over why implementation bogs down with franchise clients and why players lose track of their roles, or even overwrite one another’s efforts.
In this post, we’ll give you some quick and useful coaching on the franchise model, but if your agency just got a phone call from Orangetheory or Smoothie King, you can get the bigger playbook right away.
Imagine a post-game locker room scene. On the field, all players seemed united by the goal of winning. But now, at different press conferences, the owner is saying the coach failed to meet standards, the coach is saying the owner should keep his opinions to himself, and several of the star players are saying they didn’t get the ball enough.
Franchises can be just like that when there’s confusion over roles and goals. Read on to get a peek into the playbook we've prepared to help the team as a whole work better together:
Franchise marketing is a unique kind of activity. It does share a lot of qualities with corporate marketing (on the awareness side) and with SMB marketing (on the local side) but as we noted earlier, it’s sort of a joint custody arrangement that — like all custody arrangements — can get contentious at times.
Everyone wants the best for the brand, but everyone’s “best” is very much a matter of their own perspective and goals. Typically in this arrangement, there are at least two stakeholders, though sometimes there are more. The stakeholders and their goals tend to play out as follows:
Corporate Franchisor goals
Creating a strong brand to license more franchisors.
Controlling that brand so it isn’t negatively impacted.
Supporting franchisees with strong branding and resources so they succeed.
Master Franchisor goals
Working with corporate to protect the brand.
Licensing more local franchisors.
Supporting franchisees with resources so they succeed.
Regional or Area Franchisee goals
Driving customer traffic and revenue at individual locations.
Growing their portfolio of locations.
Supporting location managers with resources so they succeed.
Owner/Operator Franchisee goals
Increasing location(s) foot traffic.
Increasing location(s) revenue.
Building customer loyalty at the location(s).
In what ways is franchise marketing different from corporate or standard SMB marketing? There are some unique challenges that franchisors and franchisees face which are worth unpacking. Some of them are:
Conflicting goals between franchisor/franchisee
Faster turnover of locations and addresses
Different opening hours, menus and promotions from location to location
Unique local sales and marketing opportunities and challenges
Competitors on both the brand side but also among local SMBs
Lack of clearly defined marketing roles causing work to be overwritten, duplicated, or even neglected
Your agency can be a better coach to franchises by having a playbook that respects how they differ from corporate or SMB clients at the very outset. But differences don’t have to equal weaknesses. Are you ready to draft a game plan that draws from the strengths of both franchisors and franchisees?
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
from The Moz Blog https://ift.tt/2BNvMK2
via IFTTT
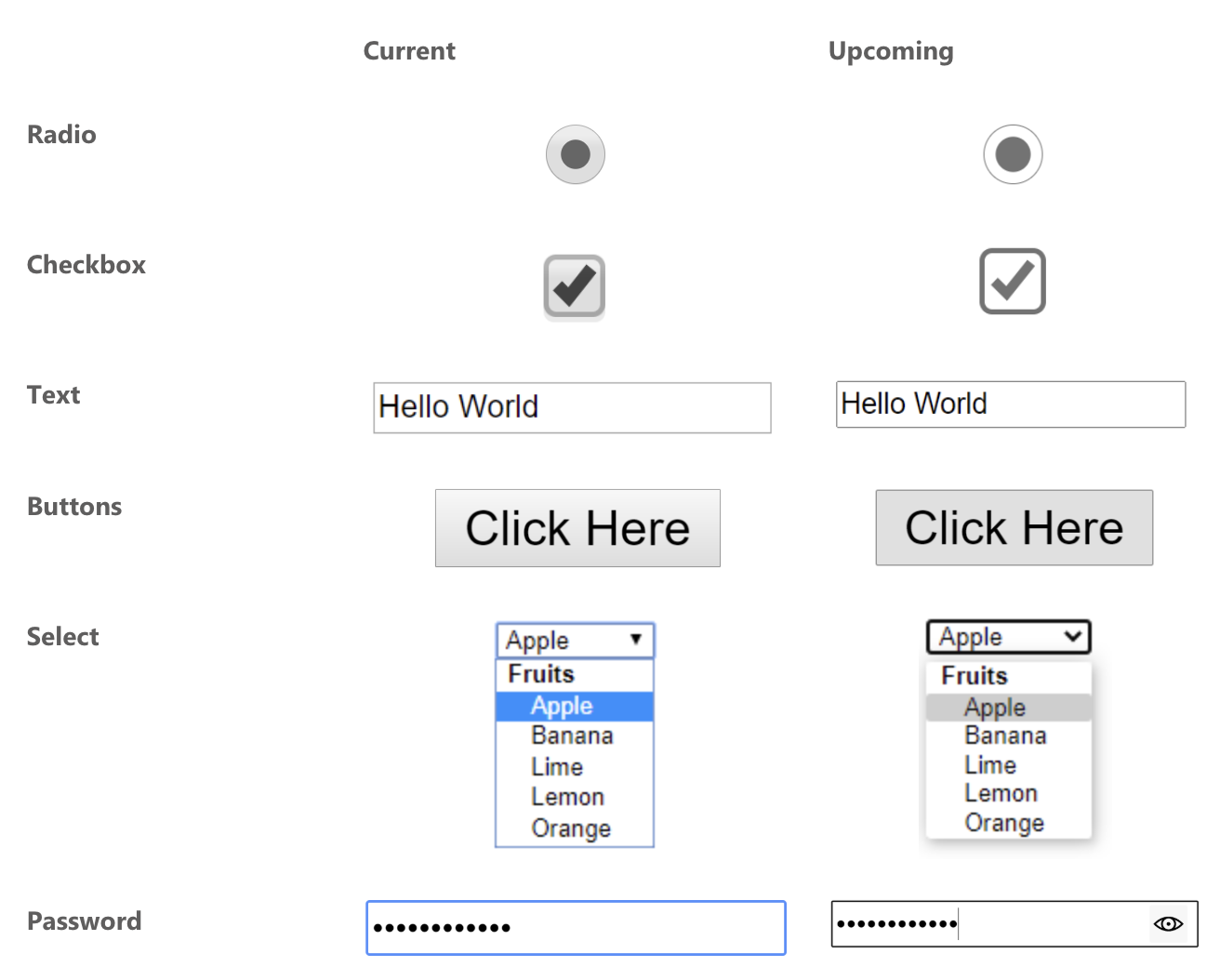
Best I could tell from the last time I compiled the most wished-for features of CSS, styling form controls was a major ask. Top 5, I'd say. And of the native form elements that people want to style, Greg Whitworth has some data that the <select> element is more requested than any other element — more than double the next element — and it's the one developers most often customize in some way.
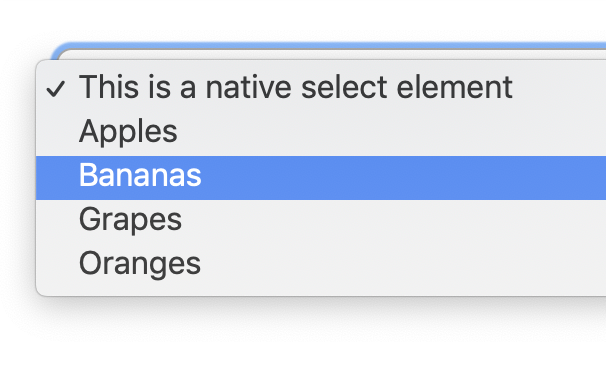
Developers clearly want to style select dropdowns.
You actually do a little. Perhaps more than you realize.
Notably, this is an entirely cross-browser solution. It's not something limited to only the most progressive desktop browsers. There are some visual differences across browsers and platforms, but overall it's pretty consistent and gives you a baseline from which to further customize it.
That's just the "outside"
Open the select. Hmm, it looks and behaves like you did nothing to it at all.
Styling a <select> doesn't do anything to the opened dropdown of items. (Screenshot from macOS Chrome)
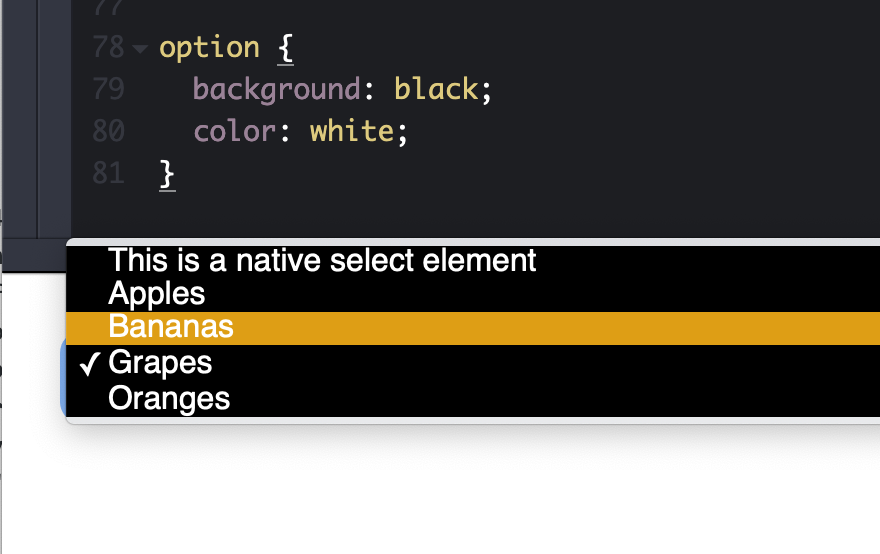
Some browsers do let you style the inside, but it's very limited. Any time I've gone down this road, I've had a bad time getting things cross-browser compliant.
Firefox letting me set the background of the dropdown and the color of a hovered option.
Greg's data shows that only 14% (third place) of developers found styling the outside to be the most painful part of select elements. I'm gonna steal his chart because it's absolutely fascinating:
Frustration
%
Count
Not being able to create a good user experience for searching within the list
27.43%
186
Not being able to style the <option> element to the extent that you needed to
17.85%
121
Not being able to style the default state (dropdown arrow, etc.)
14.01%
95
Not being able to style the pop-up window on desktop (e.g. the border, drop shadows, etc.)
11.36%
77
Insertion of content beyond simple text in the <select> control or its <option>s
11.21%
76
Insertion of arbitrary HTML content in an <option> element
7.82%
53
Not being able to create distinctive unselected/placeholder style and behavior
3.39%
23
Being able to generate new options from a large dataset while the popup is open
3.10%
21
Not being able to style the currently selected <option>(s) to the extent you needed to
1.77%
12
Not being able to style the pop-up window on mobile
1.03%
7
Being able to have the options automatically repeat on scroll (i.e., if you have an list of options 1 – 100, as you reach 100 rather than having the user scroll back to the top, have 1 show up below 100)
1.03%
7
Boiled down, the most painful parts of styling selects are:
Search
Styling the open dropdown, including the individual options, including more than just text
Updating the element without closing it
Styling for cases where "nothing" is selected and when an item is selected
I'm surprised multi-select didn't make the cut. Maybe it's not on the table for <select> since it wouldn't be backwards-compatible?
Browser evolution
Edge recently announced they are improving the look of form controls, but no word just yet on standards or how to customize them.
Select styles in Edge/Chromium before (left) and after (right)
It seems like there is good momentum, though. If you want more information and to follow along with all this progress (I know I will!):
We couldn’t do it without you! In 2018, over 1,400 marketers responded to our State of the Local SEO industry survey. We all learned so much from your responses about the day-to-day realities of marketing local businesses. This year, we can do even better because your answers will give us all valuable comparative data to analyze, YoY.
Who can take the survey?
Anyone who markets local businesses in any way is eagerly invited. Whether you market a single location, work for an agency with some local business clients, or are an in-house SEO for a brand with thousands of locations, we would love your participation! Whether you do just a little local search marketing or a lot, are a novice or an adept, your insights have value.
What is the survey about?
Unlike a typical local ranking factors poll, The State of the Local SEO Industry Survey digs deep into marketers’ experiences with tactics, challenges, clients, Google, and the working environment. For example, we learned last year that:
90% of respondents felt Google’s emphasis on proximity was detrimental to SERP quality
62% felt there aren’t enough quality local search marketing training materials available
60% lacked a comprehensive review management strategy
49% felt utilization of Google Business Profile features were impacting local rank
35% had no link building strategy in place
17% of enterprises had no in-house SEO staff
With your help, we’ll see what’s changed and what hasn’t. There are fresh questions, too, which we hope will uncover new stories to spark new strategies for local brands and their marketers.
There will be four lucky winners!
Everyone is a winner with access to the data we’ll be sharing from this large survey. But we’d like to offer a little extra thank-you for your time and knowledge.
Every respondent who completes the full survey will be automatically entered for a chance to win one of four $50 Visa gift cards. Winners will be selected at random, and we hope they will use these gift cards to shop someplace local and awesome this holiday season!
Look forward to seeing the results in early 2020. We can't wait to see what we find out this time around. Thank you for participating!
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
from The Moz Blog https://ift.tt/2PqwKUv
via IFTTT
The distance between Internet Explorer (IE) 11 and every other major browser is an increasingly gaping chasm. Adding support for a technologically obsolete browser adds an inordinate amount of time and frustration to development. Testing becomes onerous. Bug-fixing looms large. Developers have wanted to abandon IE for years, but is it now financially prudent to do so?
First off, we’re talking about a dead browser
Development of IE came to an end in 2015. Microsoft Edge was released as its replacement, with Microsoft announcing that “the latest features and platform updates will only be available in Microsoft Edge”.
Edge was a massive improvement over IE in every respect. Even so, Edge was itself so far behind in implementing web standards that Microsoft recently revealed that they were rebuilding Edge from the ground up using the same technology that powers Google Chrome.
Yet here we are, discussing whether to support Edge’s obsolete ancient relative. Internet Explorer is so bad that a Principal Program Manager at the company published a piece entitled The perils of using Internet Explorer as your default browser on the official Microsoft blog. It’s a browser frozen in time; the web has moved on.
Publications have spelled the fall of IE since 2015.
Browsers are moving faster than ever before. Consider everything that has happened since 2015. CSS Grid. Custom properties. IE11 will never implement any new features. It’s a browser frozen in time; the web has moved on.
It blocks opportunities and encourages inefficiency
The landscape of browsers has also changed dramatically since Microsoft deprecated IE in 2015. Google developer advocate Sam Thorogood has compiled a list of all the features that are supported by every browser other than IE. Once the new Chromium version of Edge is released, this list will further increase. Taken together, it’s a gargantuan feature set, comprising new HTML elements, new CSS properties and new JavaScript features. Many modern JavaScript features can be made compatible with legacy browsers through the use of polyfills and transpilation. Any CSS feature added to the web over the last four years, however, will fail to work in IE altogether.
Let’s dig a little deeper into the features we have today and how they are affected by IE11. Perhaps most notable of all, after decades of hacking layouts on the web, we finally have CSS grid, which massively simplifies responsive layout. Together with CSS custom properties, object-fit, display: contents and intrinsic sizing, they’re all examples of useful CSS features that are likely to leave a website looking broken if they’re not supported. We’ve had some major additions to CSS over the last five years. It’s the cumulative weight of so many things that undermines IE as much as one killer feature.
While many additions to the web over the last five years have been related to layout and styling, we’ve also had huge steps forwards in functionality, such as Progressive Web Apps. Not every modern API is unusable for websites that need to stay backwards compatible. Most can be wrapped in an if statement.
if ('serviceWorker' in navigator) {
// do some stuff with a service worker
} else {
// ???
}
You will, however, be delivering a very different experience to IE users. Increasingly, support for IE will limit the choice of tools that are available as library and frameworks utilize modern features.
Take this announcement from Evan You about the release of Vue 3, for example:
The new codebase currently targets evergreen browsers only and assumes baseline native ES2015 support.
The Vue 3 codebase makes use of proxies — a JavaScript feature that cannot be transpiled. MobX is another popular framework that also relies on proxies. Both projects will continue to maintain backwards-compatible versions, but they’ll lack the performance improvements and API niceties gained from dropping IE. Pika, a great new approach to package management, requires support for JavaScript modules, which are not supported in IE. Then there is shadow DOM — a standardized part of the modern web platform that is unlikely to degrade gracefully.
Supporting it takes tremendous effort
When assessing how much extra work is required to provide backwards compatibility for a deprecated browser like IE11, the long list of unimplemented features is only part of the problem. Browsers are incredibly complex pieces of software and, despite web standards, browsers are inconsistent. IE has long been the most bug-ridden browser that is most at odds with web standards. Flexbox (a technology that developers have been using since 2013), for example, is listed on caniuse.com as having partial support on IE due to the "large amount of bugs present."
IE also offers by far the worst debugging experience — with only a primitive version of DevTools. This makes fixing bugs in IE undoubtedly the most frustrating part of being a developer, and it can be massively time-consuming — taking time away from organizations trying to ship features.
There’s a difference between support — making sure something is functional and looks good enough — versus optimization, where you aim to provide the best experience possible. This does, however, create a potentially confusing grey area. There could be differences of opinion on what constitutes good enough for IE. This comment about IE9 from Dave Rupert is still relevant:
The line for what is considered "broken" is fuzzy. How visually broken does it have to be in order to be functionally broken? I look for cheap fixes, but this is compounded by the fact the offshore QA team doesn’t abide in that nuance, a defect is a defect, which gets logged and assigned to my inbox and pollutes the backlog…Whether it’s polyfills, rogue if-statements, phantom styles, or QA kickbacks; there are costs and technical debt associated with rendering this site on an ever-dwindling sliver of browsers.
If you’re going to take the approach of supporting IE functionally, even if it’s not to the nth degree, still confines you to polyfill, transpile, prefix and test on top of everything else.
Twitter displays a banner informing IE users that they will not receive the best experience and redirects users to a much older version of the Twitter website. When we think of disruptive companies that are pushing the best in web design, Monzo, Apple Music and Stripe break horribly in IE, while foregoing a warning banner.
Stripe offers no support or warning.
Why the new Chromium-powered Edge browser matters
IE usage has been on a slower downward trend following an initial dramatic fall. There’s one primary reason the browser continues to hang on: ancient business applications that don’t work in anything else. Plenty of large companies still use applications that rely on APIs that were never standardized and are now obsolete. Thankfully, the new Edge looks set to solve this issue. In a recent post, the Microsoft Edge Team explained how these companies will finally be able to abandon IE:
The team designed Internet Explorer mode with a goal of 100% compatibility with sites that work today in IE11. Internet Explorer mode appears visually like it’s just a part of the next Microsoft Edge...By leveraging the Enterprise mode site list, IT professionals can enable users of the next Microsoft Edge to simply navigate to IE11-dependent sites and they will just work.
After using the beta version for several months, I can say it’s a genuinely great browser. Dare I say, better than Google Chrome? Microsoft are already pushing it hard. Edge is the default browser for Windows 10. Hundreds of millions of devices still run earlier versions of the operating system, on which Edge has not been available. The new Chromium-powered version will bring support to both Windows 7 and 8. For users stuck on old devices with old operating systems, there is no excuse for using IE anymore. Windows 7, still one of the world’s most popular operating systems, is itself due for end-of-life in January 2020, which should also help drive adoption of Edge when individuals and businesses upgrade to Windows 10.
In other words, it's the perfect time to drop support.
Performance costs
All current browsers support ECMAScript 2015 (the latest version of JavaScript) — and have done so for quite some time. Transpiling JavaScript down to an older (and slower) version is still common across the industry, but at this point in time is needed only for Internet Explorer. This process, allowing developers to write modern syntax that still works in IE negatively impacts performance. Philip Walton, an engineer at Google, had this to say on the subject:
Larger files take longer to download, but they also take longer to parse and evaluate. When comparing the two versions from my site, the parse/eval times were also consistently about twice as long for the legacy version. [...] The cost of shipping lots of unneeded JavaScript to low-end mobile browsers can be significant! We (on the Chrome team) have seen numerous occurrences of polyfill bloat adding seconds to the total startup time of websites on low-end mobile devices.
It’s possible to take a differential serving approach to get around this issue, but it does add a small amount of complexity to build tooling. I’m not sure it’s worth bothering when looking at the entire picture of what it already takes to support IE.
Yet another example: IE requires a massive amount of polyfills if you’re going to utilize modern APIs. This normally involves sending additional, unnecessary code to other browsers in the process. An alternative approach, polyfill.io, costs an additional, blocking HTTP request — even for modern browsers that have no need for polyfills. Both of these approaches are bad for performance.
As for CSS, modern features like CSS grid decrease the need for bulky frameworks like Bootstrap. That's lots of extra bites we’re unable to shave off if we have to support IE. Other modern CSS properties can replace what’s traditionally done with JavaScript in a way that’s less fragile and more performant. It would be a boon for both performance and cost to take advantage of them.
Let’s talk money
One (overly simplistic) calculation would be to compare the cost of developer time spent on fixing IE bugs and the amount lost productivity working around IE issues versus the revenue from IE users. Unless you’re a large company generating significant revenue from IE, it’s an easy decision. For big corporations, the stakes are much higher. Websites at the scale of Amazon, for example, may generate tens of millions of dollars from IE users, even if they represent less than 1% of total traffic.
I’d argue that any site at such scale would benefit more by dropping support, thanks to reducing load times and bounce rates which are both even more important to revenue. For large companies, the question isn’t whether it’s worth spending a bit of extra development time to assure backwards compatibility. The question is whether you risk degrading the experience for the vast majority of users by compromising performance and opportunities offered by modern features. By providing no incentive for developers to care about new browser features, they're being held back from innovating and building the best product they can.
It’s a massively valuable asset to have developers who are so curious and inquisitive that they explore and keep up with new technology. By supporting IE, you’re effectively disengaging developers from what’s new. It’s dispiriting to attempt to keep up with what’s new only to learn about features we can’t use. But this isn’t about putting developer experience before user experience. When you improve developer experience, developers are enabled to increase their productivity and ship features — features that users want.
Web development is hard
It was reported earlier this year that the car rental company Hertz was suing Accenture for tens of millions of dollars. Accenture is a Fortune Global 500 company worth billions of dollars. Yet Hertz alleged that, despite an eye-watering price tag, they "never delivered a functional site or mobile app."
Among the most mind-boggling allegations in Hertz's filed complaint is that Accenture didn't incorporate a responsive design… Despite having missed the deadline by five months, with no completed elements and weighed down by buggy code, Accenture told Hertz it would cost an additional $10m – on top of the $32m it had already been paid – to finish the project.
The Accenture/Hertz affair is an example of stunning ineptitude but it was also a glaring reminder of the fact that web development is hard. Yet, most companies are failing to take advantage of things that make it easier. Microsoft, Google, Mozilla and Apple are investing massive amounts of money into developing new browser features for a reason. Improvements and innovations that have come to browsers in recent years have expanded what is possible to deliver on the web platform while making developers’ lives easier.
Move fast and ship things
The development industry loves terms — like agile and disruptive — that imply light-footed innovation. Yet rather than focusing on shipping features and creating a great experience for the vast bulk of users, we’re catering to a single outdated legacy browser. All the companies I’ve worked for have constantly talked about technical debt. The weight of legacy code is accurately perceived as something that slows down developers. By failing to take advantage of what modern browsers have to offer, the code we write today is legacy code the moment it is written. By writing for the modern web, you don’t only increase productivity today but also create code that’s easier to maintain in the future. From a long-term perspective, it’s the right decision.
Recruitment and retainment
Developer happiness won’t be viewed as important to the bottom line by some business stakeholders. However, recruiting good engineers is notoriously difficult. Average tenure is low compared to other industries. Nothing can harm developer morale more than a day of IE debugging. In a survey of 76,118 developers conducted by Mozilla "Having to support specific browsers (e.g. IE11)" was ranked as the most frustrating thing in web development. "Avoiding or removing a feature that doesn't work across browsers" came third while testing across different browsers reached fourth place. By minimising these frustrations, deciding to end support for IE can help with engineer recruitment and retainment.
IE users can still access your website
We live in a multi-device world. Some users will be lucky enough to have a computer provided by their employer, a personal laptop and a tablet. Smartphones are ubiquitous. If an IE user runs into problems using your site, they can complete the transaction on another device. Or they could open a different browser, as Microsoft Edge comes preinstalled on Windows 10.
The reality of cross-browser testing
If you have a thorough and rigorous cross-browser testing process that always gets followed, congratulations! This is rare in my experience. Plenty of companies only test in Chrome. By making cross-browser testing less onerous, it can be made more likely that developers and stakeholders will actually do it. Eliminating all bugs in browsers that are popular is far more worthwhile monetarily than catering to IE.
When do you plan to drop IE support?
Inevitably, your own analytics will be the determining factor in whether dropping IE support is sensible for you. Browser usage varies massively around the world — from almost 10% in South Korea to well below one percent in many parts of the world. Even if you deem today as being too soon for your particular site, be sure to reassess your analytics after the new Microsoft Edge lands.